What I’m Working On
(Apr-Aug 2026)
A research update, April 2026
I thought of sharing a bit about what I am working on in my educational research right now. I have lots of data analysis to keep me busy for the entire academic Summer. I shared a version of this at a poster 1 I had at the 2nd edition of the Global Approaches to Generative AI in Education conference at LSE, a joint event with KCL and Peking University. You can read my musings over what was discussed in the first day of the conference in my other post here.

Since 2023, my colleagues and I have been studying how students’ learning is impacted by the use of generative AI as they go through their studies and coursework as part of the ![]() GENIAL project at LSE. We started as a focus group trying to make sense of what was happening in our classrooms after ChatGPT arrived. That early work produced a policy piece on the risk of students bypassing their own learning process (Sallai et al., 2024) and then a research framework that maps student-GenAI interactions onto Kolb’s experiential learning cycle (Cardoso-Silva et al., 2025), a preprint that is under journal review.
GENIAL project at LSE. We started as a focus group trying to make sense of what was happening in our classrooms after ChatGPT arrived. That early work produced a policy piece on the risk of students bypassing their own learning process (Sallai et al., 2024) and then a research framework that maps student-GenAI interactions onto Kolb’s experiential learning cycle (Cardoso-Silva et al., 2025), a preprint that is under journal review.
The framework paper drew on case studies from six courses across LSE and now that it exists, I want to put it to the test with a full cohort, richer data, and enough volume to see whether the patterns hold up quantitatively. This kind of close reading is far too labour-intensive for routine marking. At this stage the work is purely research, but whatever patterns hold up will later inform how we plan courses and assessments and what guidance we offer students and educators about working with AI.
(I am doing this as part of a fellowship I received from the LSE AI and Education Fellowship programme (2025–2027) which has as the main goal to build a proactive AI tutor to help students feel more connected with their learning process throughout their studies. I’ll write more about that in the future!)
The data
This past academic year I collected data from a full cohort of DS105W, my introductory data science and programming course at LSE, which about a hundred undergraduates from various disciplines take each year. Of the 103 students enrolled, 83 consented to participate in the study. That is just over 80%, which I did not expect and am extremely grateful for!
Not everyone was comfortable sharing all of their data, so consent came at two levels. I asked them if they were happy to share their chat logs (C1) and their coursework (C2), which involves the final version of their coursework as well as the version history and intermediary versions too (git commits), plus the feedback and grades they received for their work 1.
Here’s how much data I have from the students, broken down by data type and consent level:
| Consent level | Students | Git commits | Chat exchanges |
|---|---|---|---|
| Chat logs, git histories, and grades | 53 | 1,689 | 9,721 |
| Full consent, but no AI tools used | 7 | 102 | 0 |
| Git histories and grades only | 23 | 637 | — |
| Did not consent | 20 | — | — |
The first of these groups is the richest: I can see what they asked the AI, what the AI said, what they did next in their code, and how the submitted work was graded. The seven who gave full consent but submitted no chat logs either chose not to use AI tools or forgot to save their conversations 2 The third group agreed to share their code histories and grades but not their conversations with AI. I can see how their work evolved and how it was graded, but not the exchanges that may have informed it. I am still thinking about how to handle this group for the analysis. There is a chance this group contains students who did not use AI and that would increase my sample size that I can compare with the “full consent” group. I should be able to ascertain if they used AI or not based on their self-reports, but as my personal experience and the literature tell me, we should not trust self-reports alone. I will also consider any behavioural hints in the git histories as an indication one way or the other.
From the fifty-three students who shared everything, the dataset spans nearly three months of coursework across three assessment points. That is a lot of material to work through! Each student’s record is a timeline: chat exchanges and code snapshots interleaved in the order they happened, with the graded submissions as anchor points. Reading a single student’s full record means following their working process across weeks, watching where they got stuck, how they used the tools available to them, and what ended up in the final submission. I am now beginning the analysis, applying an expanded version of the ![]() GENIAL codebook to see whether the engagement patterns from the framework paper appear in this larger, richer dataset, and whether they relate to how students performed on the coursework.
GENIAL codebook to see whether the engagement patterns from the framework paper appear in this larger, richer dataset, and whether they relate to how students performed on the coursework.
Why this course
DS105W is experiential by design: students learn to write code, collect real data, analyse it, and communicate what they found, building up skills and tools week by week. The syllabus gives a sense of the progression:
| Week | Focus |
|---|---|
| W01 | Data exploration with pandas and notebooks |
| W02 | Python foundations; first API call |
| W03 | File I/O, JSON and CSV; Git setup 📋 W04 Practice released (formative) |
| W04 | Full data pipeline: API to JSON to analysis to CSV 📋 W04 Practice due (formative) ✍️ Mini-Project 1 released (20%) |
| W05 | pandas transformations; seaborn visualisation |
| W06 | Reading Week. ✍️ Mini-Project 1 due (20%) |
| Week | Focus |
|---|---|
| W07 | New API (TfL), emphasis on methodology design. ✍️ Mini-Project 2 released (30%) |
| W08 | Reshaping and merging data |
| W09 | Principled exploratory data analysis; DOs and DON’Ts in data visualisation |
| W10 | SQL introduction; using Git as teams |
| W11 | Agentic AI coding; group project formation. ✍️ Mini-Project 2 due 📦 Group Project released (50%) (the group project is not covered in the study) |
The three assessment points where I collected data for the study are the 📋 W04 Practice, ✍️ Mini-Project 1, and ✍️ Mini-Project 2. Students use Git for version control throughout from Week 03, and the assignments are structured around milestones where they commit their progress: data collected, analysis written, reflection added, code revised. Each commit is a timestamped snapshot of what changed (new code, updated reflections, revised documentation) together with the student’s own description of what they did. (The course is quite demanding in terms of the amount of work students have to do, but I promise most of them love having gone through it!)
Students also had access to a Claude tutor I built on LSE’s Enterprise Anthropic subscription, configured with the course materials and anchored to what we were teaching each week. I’ve presented about this internally at the LSE but I haven’t written about it publicly yet, so I will save the details for a future post. Some students used personal ChatGPT accounts instead, or alongside. Both produce timestamped chat logs.
When a student’s chat log and their git history are read side by side, the combination shows something neither source shows alone: whether the code the student committed came from the AI, from the course materials, or from the student’s own thinking. That is what makes this dataset unusually rich for studying how AI mediates learning: I can follow a student from the question they asked, through the AI’s response, to what they actually did with it in their code.
The framework
The ![]() GENIAL framework is how I plan to make sense of all this data.
GENIAL framework is how I plan to make sense of all this data.
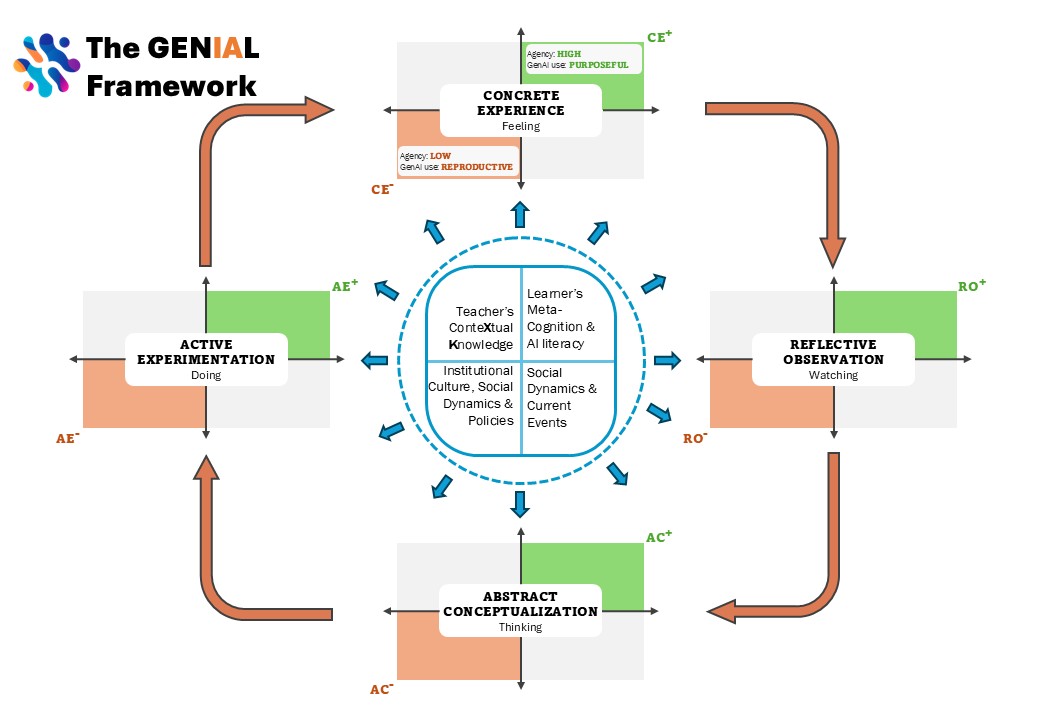
It works from the raw record of a student’s interaction with AI and the version history of their work. We code each exchange: what the student asked, what the AI returned, and what the student did with the response (whether they adopted the AI’s output into their own work unchanged, modified it, or produced something different). We then identify where one sub-task ends and the next begins, grouping exchanges into learning cycles.
Kolb’s experiential learning model describes learning as a cycle: try something, reflect on what happened, connect it to what you know, try again differently. Each cycle is mapped onto those four stages: CE (concrete experience), RO (reflective observation), AC (abstract conceptualisation), and AE (active experimentation). Our addition to Kolb is assessing each stage based on whether the student’s agency and their use of GenAI catalysed (+) or disrupted (-) that part of the learning process. For example: RO- means the student moved past the AI’s output without examining whether it matched what they expected or intended, while AC+ means we saw the student playing with the AI’s response to generate new ideas and insights, catalysing their abstract conceptualisation.
From the profile of each cycle, we can then label how GenAI mediated the student’s learning: Receptive (the student accepts what the AI provides and builds on it uncritically), Resourceful (the student directs the AI, adapts its output, and tests alternatives), Reflective, Resistive, or Riffing, a taxonomy extended from Yang et al. (2024). These patterns are contextually determined rather than fixed: the same student can shift between them across assignments, depending on how much they know about the topic, how much time they have, and how complex the task is.
What comes next
Over the coming months I will be working through this data. I have also been reading and writing about the broader question of how generative AI changes what students learn, starting with “The Wrong Test” and continuing in upcoming posts on process-based assessment and the conditions under which AI use helps learning rather than replacing it.
If you saw the poster at the conference, or if any of this connects to work you are doing, I would be glad to hear from you.
References
Footnotes
presenting a poster brought up good memories of attending conferences as a PhD student, minus the nervousness!↩︎