🤖 Using an Agentic AI Strategy to Scale Rigorous Feedback
Human-in-the-Loop Assessment for Complex Coding Projects
Dr Jon Cardoso-Silva
📧 J.Cardoso-Silva@lse.ac.uk
📧 J.Cardoso-Silva@lse.ac.uk

29 Oct 2025
Context is everything!
Before I show you how the marking bot works, let me explain the learning activity used in this experiment ⏩
The Background Context

I teach this course called DS105 - Data for Data Science. It is a very hands-on course and it is intense! (🌐 https://lse-dsi.github.io/DS105).
Pedagogical make-up
- Continuous assessment with weekly problem sets
- Productive struggle: students work on new topics before I introduce them in the lecture. (Engage in Concrete Experience, in Kolb’s language)
- Frequent feedback cycles: In the lecture (Thursdays), I resolve the tension students experienced with the exercise (Mon-Thu).
- Group-level feedback: 📝 W01, 📝 W02 and 📝 W03 exercises
- Individual feedback: 📝 W04 Practice
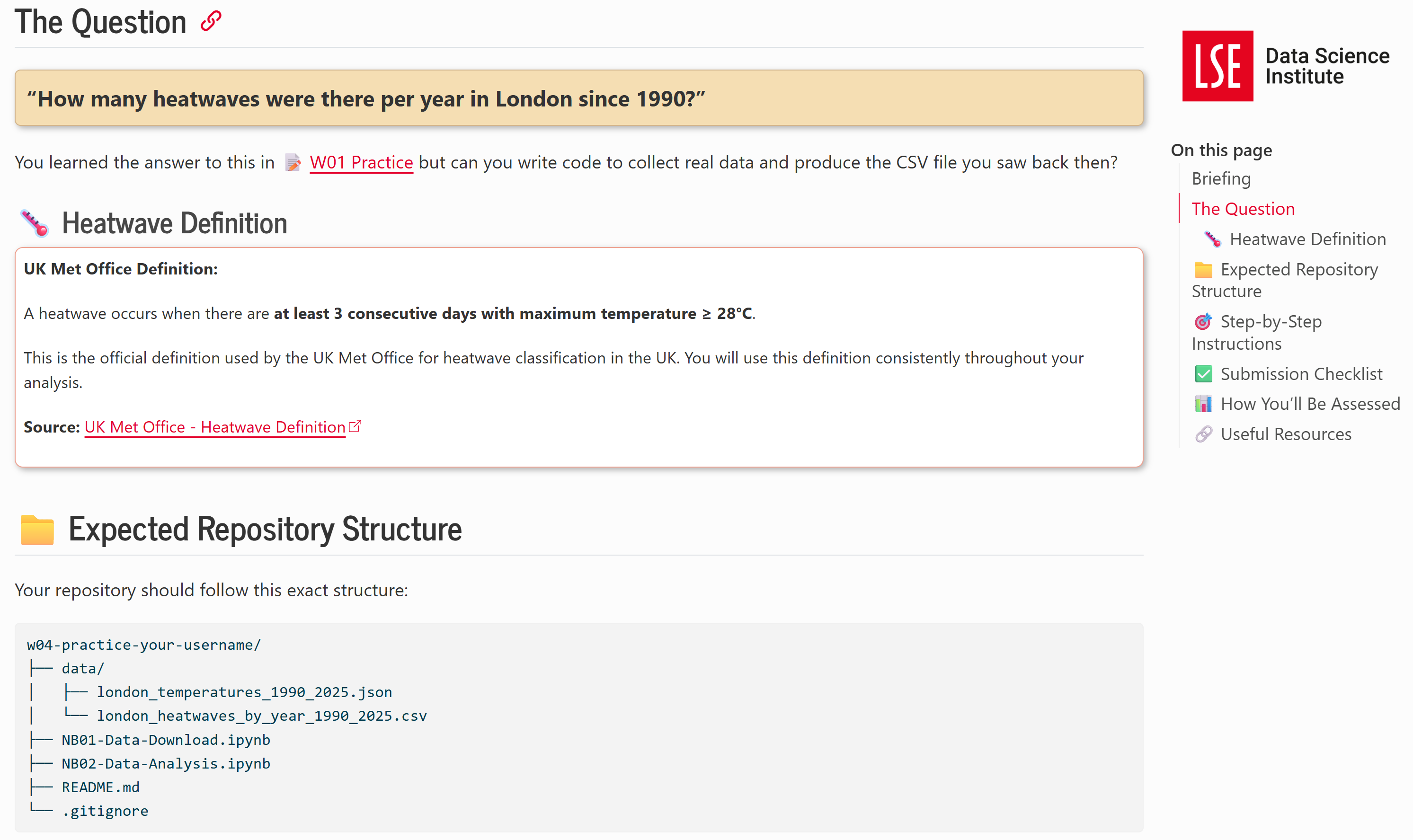
About the 📝 W04 Practice Assignment
Students’ first full data science project. Lots of imitative reasoning at this stage[1] plus reflection prompts.
They are given:
- A particular data source
- A specific (objective) exploratory question
- A fixed structure of files to follow
Deadline: 6 days!
[1] Lithner, J. (2015). Learning Mathematics by Creative or Imitative Reasoning. In S. J. Cho (Ed.), Selected Regular Lectures from the
12th International Congress on Mathematical Education (pp. 487–506). Springer International Publishing.
The marking process
I won’t stop to read all of that but I just want to show you how detailed the feedback is ⏩
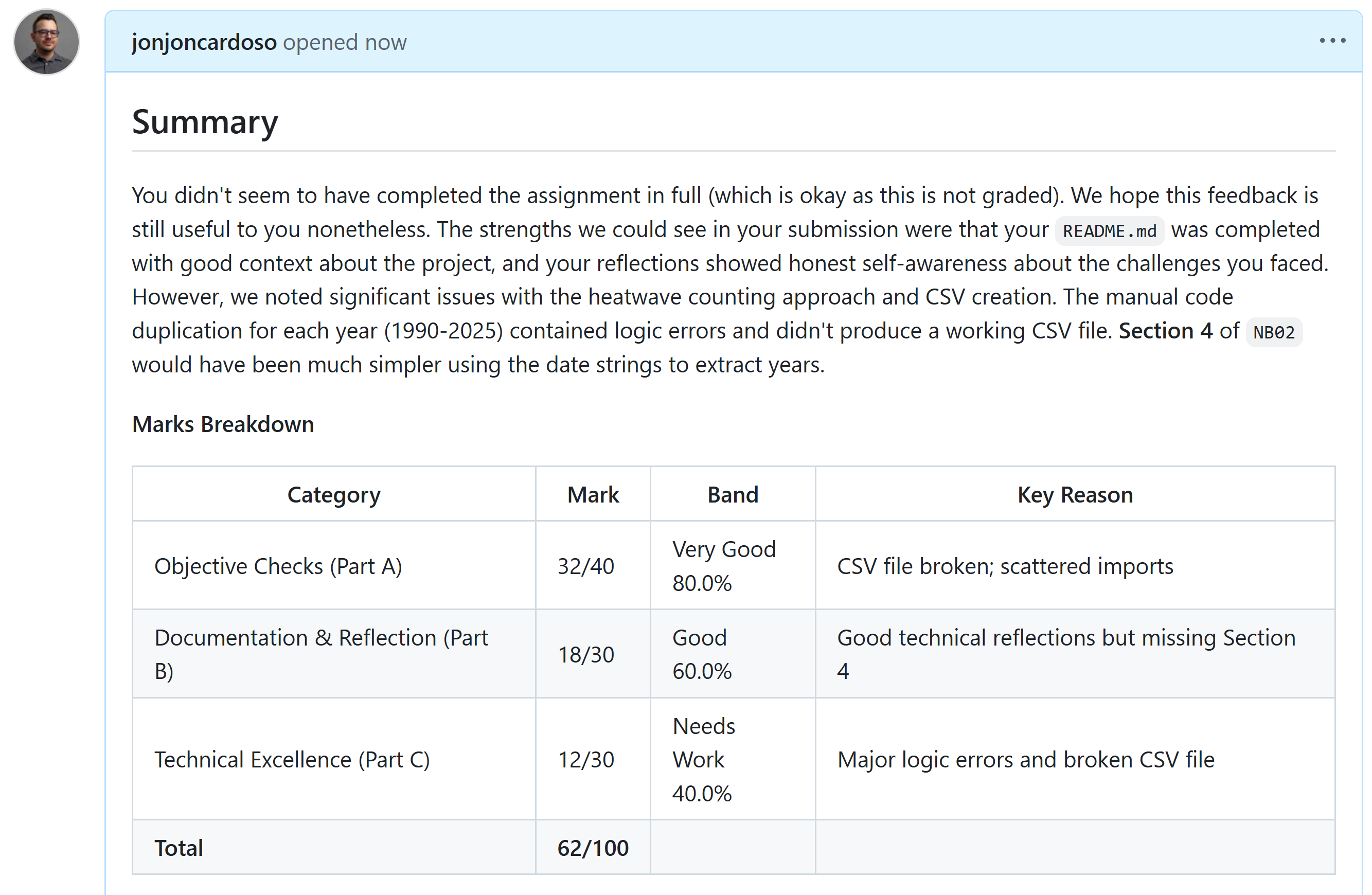
Example of feedback (1/4)
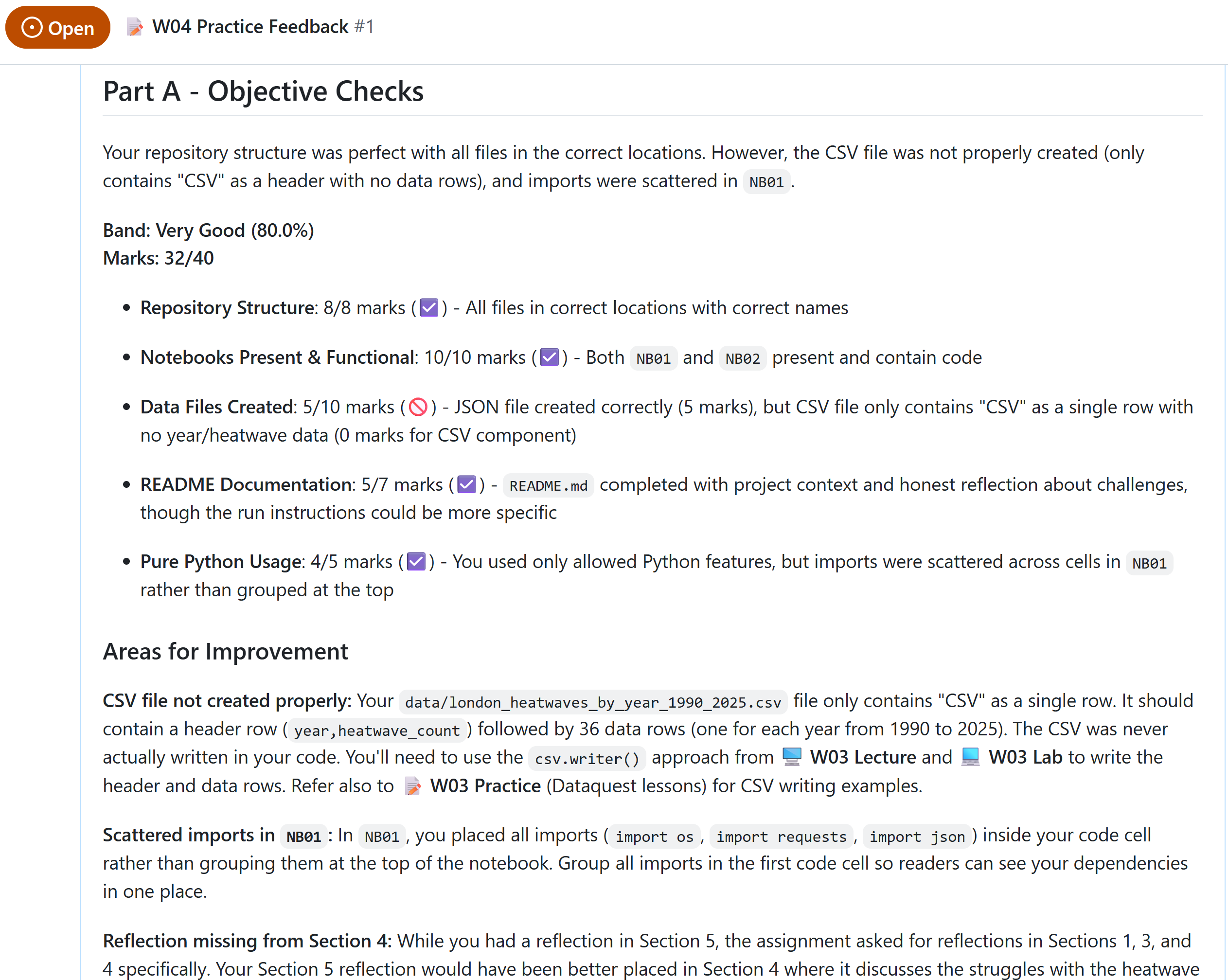
Example of feedback (2/4)
Example of feedback (3/4)
Example of feedback (4/4)
How to mark this?
Part A:
Is everything in the right place? Does the submission check all the boxes?
Part C: (Yes, BEFORE Part B)
Read
NB01andNB02and check if solution is technically accurate and, crucially, aligned with the course philosophy.Default LLM-generate code is awful! Definitely not aligned with our teaching.
Part B:
Read reflections made by students in
NB01andNB02and check if:- Does it match the technical details we see?
- Does it align with what we said in class?
Time constraints
65 students out of 83 engaged with this (optional) assignment, 📝 W04 Practice.
I want students to receive feedback within a week, before their next deadline (W06):
✍️ Mini Project I which is worth 20% of their grade.
If marking a submission takes 30 min that is a 32.5 hours job!
🤖 The AI-assisted marking workflow
What a autograder_facts.json look like
{
"repo": "C:\\Users\\Jon\\Workspace\\teaching-workspace\\w04-practice-ds105a-2025-submissions\\w04-practice-ds105a-2025-STUDENT-REPO",
"username": "STUDENT-REPO",
"structure": {
"structure_ok": true,
"missing_files": [],
"extra_files": [],
"required_files_checklist": [
"\u2705 README.md",
"\u2705 .gitignore",
"\u2705 NB01-Data-Download.ipynb",
"\u2705 NB02-Data-Analysis.ipynb",
"\u2705 data/london_temperatures_1990_2025.json",
"\u2705 data/london_heatwaves_by_year_1990_2025.csv"
],
"file_tree": [
"w04-practice-ds105a-2025-STUDENT-REPO/",
" autograder_brief.md",
" autograder_facts.json",
" NB01-Data-Download.ipynb",
" NB01-Data-Download.py",
" NB02-Data-Analysis.ipynb",
" NB02-Data-Analysis.py",
" data/",
" london_heatwaves_by_year_1990_2025.csv",
" london_temperatures_1990_2025.json",
" notebooks_py/",
" NB01-Data-Download.py",
" NB02-Data-Analysis.py"
],
"notebook_locations": {
"nb01_found": true,
"nb02_found": true,
"nb01_path": "C:\\Users\\Jon\\Workspace\\teaching-workspace\\w04-practice-ds105a-2025-submissions\\w04-practice-ds105a-2025-STUDENT-REPO\\NB01-Data-Download.ipynb",
"nb02_path": "C:\\Users\\Jon\\Workspace\\teaching-workspace\\w04-practice-ds105a-2025-submissions\\w04-practice-ds105a-2025-STUDENT-REPO\\NB02-Data-Analysis.ipynb",
"all_notebooks": [
"C:\\Users\\Jon\\Workspace\\teaching-workspace\\w04-practice-ds105a-2025-submissions\\w04-practice-ds105a-2025-STUDENT-REPO\\NB01-Data-Download.ipynb",
"C:\\Users\\Jon\\Workspace\\teaching-workspace\\w04-practice-ds105a-2025-submissions\\w04-practice-ds105a-2025-STUDENT-REPO\\NB02-Data-Analysis.ipynb"
]
},
"data_file_locations": {
"json_found": true,
"csv_found": true,
"json_path": "C:\\Users\\Jon\\Workspace\\teaching-workspace\\w04-practice-ds105a-2025-submissions\\w04-practice-ds105a-2025-STUDENT-REPO\\data\\london_temperatures_1990_2025.json",
"csv_path": "C:\\Users\\Jon\\Workspace\\teaching-workspace\\w04-practice-ds105a-2025-submissions\\w04-practice-ds105a-2025-STUDENT-REPO\\data\\london_heatwaves_by_year_1990_2025.csv",
"all_json_files": [
"C:\\Users\\Jon\\Workspace\\teaching-workspace\\w04-practice-ds105a-2025-submissions\\w04-practice-ds105a-2025-STUDENT-REPO\\autograder_facts.json",
"C:\\Users\\Jon\\Workspace\\teaching-workspace\\w04-practice-ds105a-2025-submissions\\w04-practice-ds105a-2025-STUDENT-REPO\\data\\london_temperatures_1990_2025.json"
],
"all_csv_files": [
"C:\\Users\\Jon\\Workspace\\teaching-workspace\\w04-practice-ds105a-2025-submissions\\w04-practice-ds105a-2025-STUDENT-REPO\\data\\london_heatwaves_by_year_1990_2025.csv"
]
},
"notebook_location_issues": {
"nb01_expected": "NB01-Data-Download.ipynb",
"nb01_actual": "NB01-Data-Download.ipynb",
"nb01_status": "correct",
"nb02_expected": "NB02-Data-Analysis.ipynb",
"nb02_actual": "NB02-Data-Analysis.ipynb",
"nb02_status": "correct",
"structure_penalty": false,
"assessment_possible": true
},
"data_file_location_issues": {
"json_expected": "data/london_temperatures_1990_2025.json",
"json_actual": "data\\london_temperatures_1990_2025.json",
"json_status": "correct",
"csv_expected": "data/london_heatwaves_by_year_1990_2025.csv",
"csv_actual": "data\\london_heatwaves_by_year_1990_2025.csv",
"csv_status": "correct",
"structure_penalty": false,
"assessment_possible": true
}
},
"notebook_locations": {
"nb01_path": "C:\\Users\\Jon\\Workspace\\teaching-workspace\\w04-practice-ds105a-2025-submissions\\w04-practice-ds105a-2025-STUDENT-REPO\\NB01-Data-Download.ipynb",
"nb02_path": "C:\\Users\\Jon\\Workspace\\teaching-workspace\\w04-practice-ds105a-2025-submissions\\w04-practice-ds105a-2025-STUDENT-REPO\\NB02-Data-Analysis.ipynb",
"all_notebooks": [
"C:\\Users\\Jon\\Workspace\\teaching-workspace\\w04-practice-ds105a-2025-submissions\\w04-practice-ds105a-2025-STUDENT-REPO\\NB01-Data-Download.ipynb",
"C:\\Users\\Jon\\Workspace\\teaching-workspace\\w04-practice-ds105a-2025-submissions\\w04-practice-ds105a-2025-STUDENT-REPO\\NB02-Data-Analysis.ipynb"
]
},
"nb01_headings": {
"headings_found": [],
"headings_missing": [],
"hierarchy": [
"H1: \ud83d\udcdd W04 Practice: London Heatwave Analysis (1990-2025)"
]
},
"nb02_headings": {
"headings_found": [
"Section 1: Data Loading",
"Section 2: Identifying Hot Days",
"Section 3: Subset of Hot Days",
"Section 4: Recreating the CSV",
"Section 5: AI Usage Documentation"
],
"headings_missing": [],
"hierarchy": [
"H1: \ud83d\udcca W04 Practice: London Heatwave Analysis (1990-2025)",
" H2: Section 1: Data Loading",
" H2: Section 2: Identifying Hot Days",
" H2: Section 3: Subset of Hot Days",
" H2: Section 4: Recreating the CSV",
" H2: Section 5: AI usage documentation",
" H2: Personal Reflection"
]
},
"nb01_imports": {
"top_grouped": false,
"scattered_imports": [
{
"cell_index": 3,
"line": "import os"
},
{
"cell_index": 3,
"line": "import requests"
},
{
"cell_index": 3,
"line": "import json"
}
],
"allowlist_only": true,
"forbidden_found": [],
"imports_at_top": [
"import requests",
"import json"
]
},
"nb02_imports": {
"top_grouped": true,
"scattered_imports": [],
"allowlist_only": true,
"forbidden_found": [],
"imports_at_top": [
"import json"
]
},
"nb01_placeholders": {
"placeholder_issues": [],
"candidate_number_issues": [],
"purpose_statements": [],
"reflection_placeholders": []
},
"nb02_placeholders": {
"placeholder_issues": [],
"candidate_number_issues": [
{
"cell_index": 0,
"type": "wrong_candidate_format",
"line": "**LSE Candidate Number:** REDACTED",
"issue": "Student ID used instead of 5-digit LSE candidate number"
}
],
"purpose_statements": [],
"reflection_placeholders": []
},
"nb01_code_stats": {
"data_inspection_prints": 0,
"hanging_objects": 0,
"short_variable_names": [],
"cell_lengths": [
3,
10,
1,
25
],
"markdown_lengths": [
13,
3
],
"error_handling": 0
},
"nb02_code_stats": {
"data_inspection_prints": 0,
"hanging_objects": 0,
"short_variable_names": [],
"cell_lengths": [
10,
8,
8,
8,
19,
469
],
"markdown_lengths": [
14,
1,
3,
1,
1,
3,
1,
1,
4,
4
],
"error_handling": 0
},
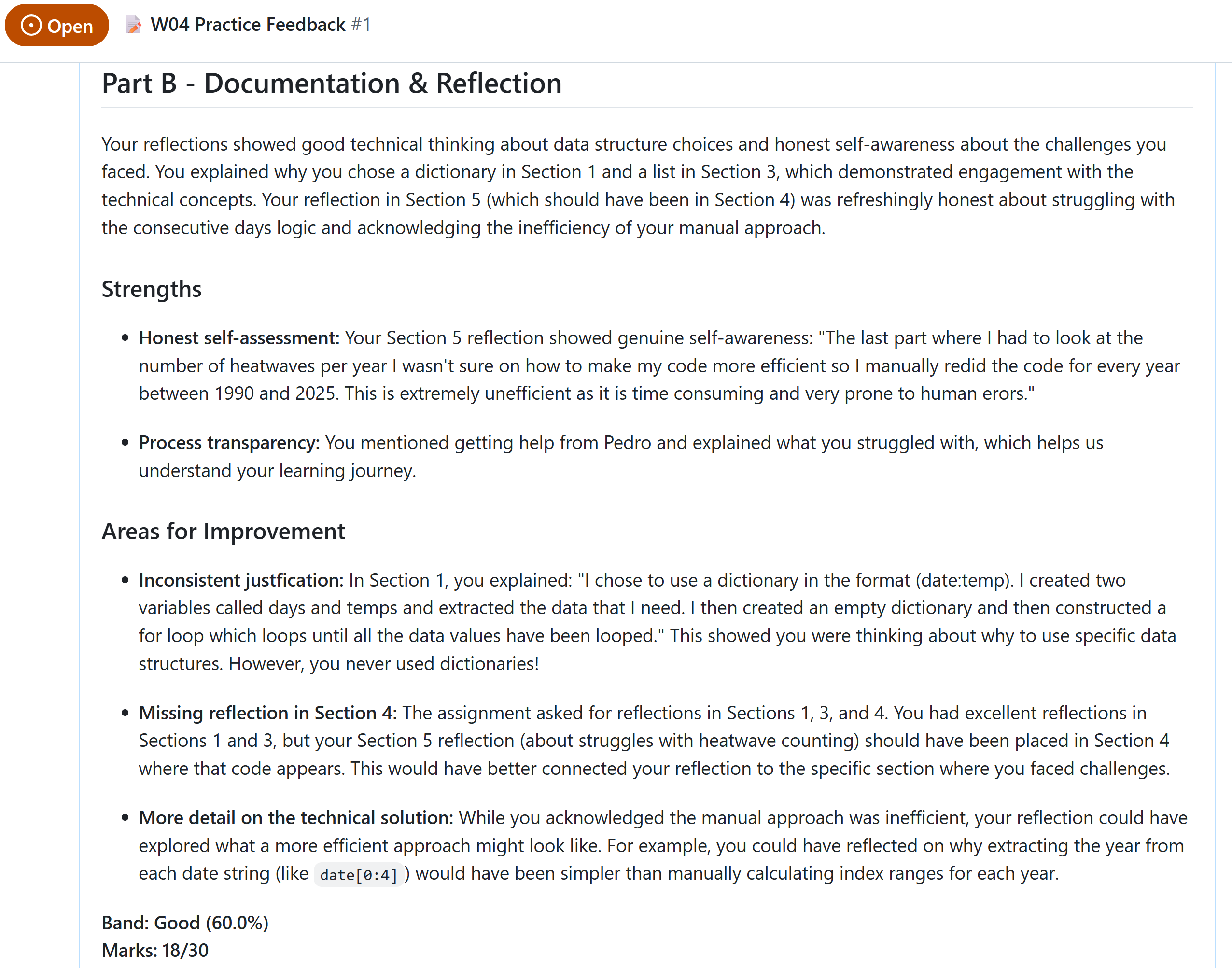
"nb01_reflections": {
"reflection_cells": [
{
"cell_index": 5,
"content": "\ud83d\udcad **Personal Reflection Note:**\n\nI first went to the Open-Meteo website and obtained the max daily temperatures between the years 1990 - 2025. I then requested the API and copied the code into a python cell. I saved the data to a json called london_temperatures_1990_2025. Now it stored in the data file in W04 practise so I do not have to constantly request the data from the API.",
"location": "anywhere_in_notebook",
"is_template": false
}
],
"reflection_count": 1,
"expected_locations": [
"anywhere_in_notebook"
],
"found_locations": [
"anywhere_in_notebook"
],
"template_locations": []
},
"nb02_reflections": {
"reflection_cells": [
{
"cell_index": 4,
"content": "\ud83d\udcad **Personal Reflection Note:**\n\nI chose to use a dictionary in the format (date:temp). I created two variables called days and temps and extracted the data that I need. I then created an empty dictionary and then constructed a for loop which loops until all the data values have been looped. After every loop the data will then be inputted into the dictionary and outputs each given date with its corresponding temperature. ",
"location": "section_1",
"is_template": false
},
{
"cell_index": 9,
"content": "\ud83d\udcad **Personal Reflection Note:**\n\nI chose to use a list for the hot_days. It gives an output of the date and its temperature on that given day. This isolates the hot days from the non hot days as I used a for loop to do so. Using a list will be easy to use later on hence why it was used.",
"location": "section_3",
"is_template": false
},
{
"cell_index": 15,
"content": "## Personal Reflection\n\nI struggled to create the for loop for the number of heatwaves as I was confused on how to reiterate the loop to look for consecutive days. However after receiving help from Pedro I managed to complete it. The last part where I had to look at the number of heatwaves per year I wasn't sure on how to make my code more efficient so I manually redid the code for every year between 1990 and 2025. This is extremely unefficient as it is time consuming and very prone to human erors. However, the code runs successfully without any errors.\n",
"location": "section_5",
"is_template": false
}
],
"reflection_count": 3,
"expected_locations": [
"section_1",
"section_3",
"section_4"
],
"found_locations": [
"section_1",
"section_3",
"section_5"
],
"template_locations": []
},
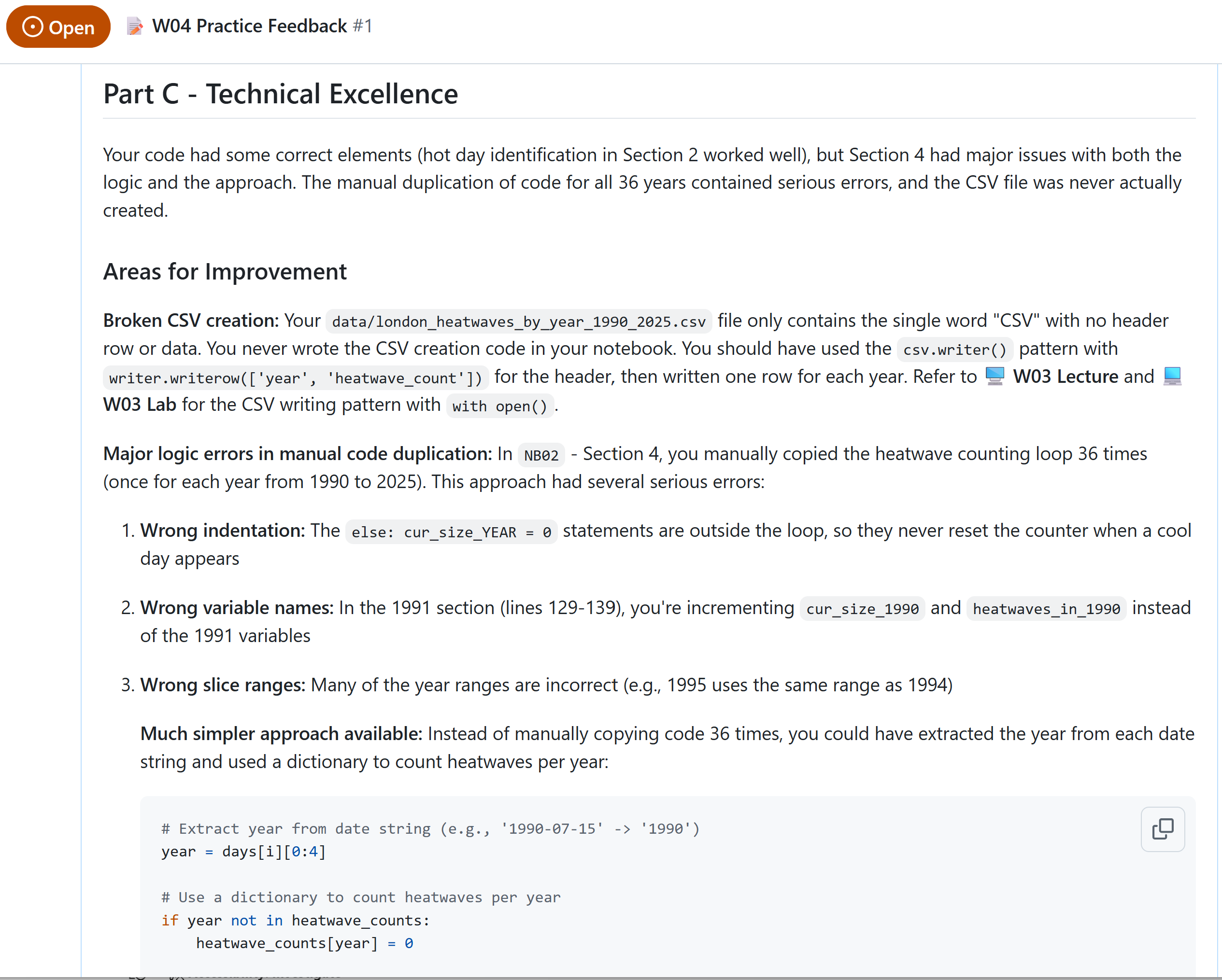
"csv_check": {
"matched": false,
"header_correct": false,
"exact_match": false,
"non_zero_only_match": false,
"diffs": [
{
"type": "header",
"expected": [
"year",
"heatwave_count"
],
"found": [
"CSV"
]
}
],
"error": null
},
"commits": {
"commits_present": true,
"exact_matches": [
{
"commit": "Add comprehensive README documentation",
"template": "Add comprehensive README documentation",
"ratio": 1.0
},
{
"commit": "Complete NB02 Section 2: Identifying Hot Days",
"template": "Complete NB02 Section 2: Identifying Hot Days",
"ratio": 1.0
},
{
"commit": "Complete NB01: Collect temperature data from Open-Meteo API#",
"template": "Complete NB01: Collect temperature data from Open-Meteo API",
"ratio": 0.9915966386554622
}
],
"partial_matches": [
{
"commit": "Complete NB02 Section 5: AI Usage Documentation and finalise NB02",
"template": "Complete NB02 Section 5: AI Usage Documentation",
"ratio": 0.8392857142857143
},
{
"commit": "Complete NB02 Section 3: Subset of Hot Days with reflection notes",
"template": "Complete NB02 Section 3: Subset of Hot Days",
"ratio": 0.7962962962962963
},
{
"commit": "Complete NB02 Section 1: Data Loading with reflection notes",
"template": "Complete NB02 Section 1: Data Loading",
"ratio": 0.7708333333333334
}
],
"missing_templates": [
"Complete NB02 Section 1: Data Loading",
"Complete NB02 Section 3: Subset of Hot Days",
"Complete NB02 Section 4: Recreating the CSV",
"Complete NB02 Section 5: AI Usage Documentation"
],
"unmatched_commits": [
"Test",
"Incomplete NB02",
"Update NB01-Data-Download.ipynb"
],
"setup_commits": [
"add deadline",
"Initial commit"
],
"student_commits": [
"Add comprehensive README documentation",
"Complete NB02 Section 5: AI Usage Documentation and finalise NB02",
"Test",
"Incomplete NB02",
"Update NB01-Data-Download.ipynb",
"Complete NB02 Section 3: Subset of Hot Days with reflection notes",
"Complete NB02 Section 2: Identifying Hot Days",
"Complete NB02 Section 1: Data Loading with reflection notes",
"Complete NB01: Collect temperature data from Open-Meteo API#"
],
"all_commits": [
"Add comprehensive README documentation",
"Complete NB02 Section 5: AI Usage Documentation and finalise NB02",
"Test",
"Incomplete NB02",
"Update NB01-Data-Download.ipynb",
"Complete NB02 Section 3: Subset of Hot Days with reflection notes",
"Complete NB02 Section 2: Identifying Hot Days",
"Complete NB02 Section 1: Data Loading with reflection notes",
"Complete NB01: Collect temperature data from Open-Meteo API#",
"add deadline",
"Initial commit"
],
"total_commits": 11,
"student_commit_count": 9,
"ai_usage": {
"section_found": false,
"link_like_text": false,
"links_found": [],
"section_content": []
},
"is_empty_submission": false,
"notebook_py_exports": {
"nb01_py": "C:\\Users\\Jon\\Workspace\\teaching-workspace\\w04-practice-ds105a-2025-submissions\\w04-practice-ds105a-2025-STUDENT-REPO\\notebooks_py\\NB01-Data-Download.py",
"nb01_original_path": "C:\\Users\\Jon\\Workspace\\teaching-workspace\\w04-practice-ds105a-2025-submissions\\w04-practice-ds105a-2025-STUDENT-REPO\\NB01-Data-Download.ipynb",
"nb02_py": "C:\\Users\\Jon\\Workspace\\teaching-workspace\\w04-practice-ds105a-2025-submissions\\w04-practice-ds105a-2025-STUDENT-REPO\\notebooks_py\\NB02-Data-Analysis.py",
"nb02_original_path": "C:\\Users\\Jon\\Workspace\\teaching-workspace\\w04-practice-ds105a-2025-submissions\\w04-practice-ds105a-2025-STUDENT-REPO\\NB02-Data-Analysis.ipynb"
},
"csv_structure": {
"exists": true,
"header_correct": false,
"duplicates_found": false,
"sorted_by_year": true
},
"evidence_markers": [
{
"marker_id": "W04-CONSTRAINTS-PY",
"status": "pass",
"evidence": {
"nb01": {
"top_grouped": false,
"scattered_imports": [
{
"cell_index": 3,
"line": "import os"
},
{
"cell_index": 3,
"line": "import requests"
},
{
"cell_index": 3,
"line": "import json"
}
],
"allowlist_only": true,
"forbidden_found": [],
"imports_at_top": [
"import requests",
"import json"
]
},
"nb02": {
"top_grouped": true,
"scattered_imports": [],
"allowlist_only": true,
"forbidden_found": [],
"imports_at_top": [
"import json"
]
}
}
},
{
"marker_id": "W04-HEADINGS-NB02",
"status": "pass",
"evidence": {
"nb02_headings": {
"headings_found": [
"Section 1: Data Loading",
"Section 2: Identifying Hot Days",
"Section 3: Subset of Hot Days",
"Section 4: Recreating the CSV",
"Section 5: AI Usage Documentation"
],
"headings_missing": [],
"hierarchy": [
"H1: \ud83d\udcca W04 Practice: London Heatwave Analysis (1990-2025)",
" H2: Section 1: Data Loading",
" H2: Section 2: Identifying Hot Days",
" H2: Section 3: Subset of Hot Days",
" H2: Section 4: Recreating the CSV",
" H2: Section 5: AI usage documentation",
" H2: Personal Reflection"
]
}
}
},
{
"marker_id": "W04-CSV-WRITE",
"status": "fail",
"evidence": {
"csv_check": {
"matched": false,
"header_correct": false,
"exact_match": false,
"non_zero_only_match": false,
"diffs": [
{
"type": "header",
"expected": [
"year",
"heatwave_count"
],
"found": [
"CSV"
]
}
],
"error": null
},
"csv_struct": {
"exists": true,
"header_correct": false,
"duplicates_found": false,
"sorted_by_year": true
}
}
},
{
"marker_id": "W04-CSV-NONZERO-ONLY",
"status": "pass",
"evidence": {
"csv_check": {
"matched": false,
"header_correct": false,
"exact_match": false,
"non_zero_only_match": false,
"diffs": [
{
"type": "header",
"expected": [
"year",
"heatwave_count"
],
"found": [
"CSV"
]
}
],
"error": null
}
}
},
{
"marker_id": "W04-CSV-DUPLICATES",
"status": "pass",
"evidence": {
"csv_struct": {
"exists": true,
"header_correct": false,
"duplicates_found": false,
"sorted_by_year": true
}
}
},
{
"marker_id": "W04-CSV-SORTED",
"status": "pass",
"evidence": {
"csv_struct": {
"exists": true,
"header_correct": false,
"duplicates_found": false,
"sorted_by_year": true
}
}
},
{
"marker_id": "W04-AI-DOC",
"status": "fail",
"evidence": {
"ai_usage": {
"section_found": false,
"link_like_text": false,
"links_found": [],
"section_content": []
}
}
},
{
"marker_id": "W04-COMM-REFLECTION",
"status": "minor",
"evidence": {
"nb02_reflections": {
"reflection_cells": [
{
"cell_index": 4,
"content": "\ud83d\udcad **Personal Reflection Note:**\n\nI chose to use a dictionary in the format (date:temp). I created two variables called days and temps and extracted the data that I need. I then created an empty dictionary and then constructed a for loop which loops until all the data values have been looped. After every loop the data will then be inputted into the dictionary and outputs each given date with its corresponding temperature. ",
"location": "section_1",
"is_template": false
},
{
"cell_index": 9,
"content": "\ud83d\udcad **Personal Reflection Note:**\n\nI chose to use a list for the hot_days. It gives an output of the date and its temperature on that given day. This isolates the hot days from the non hot days as I used a for loop to do so. Using a list will be easy to use later on hence why it was used.",
"location": "section_3",
"is_template": false
},
{
"cell_index": 15,
"content": "## Personal Reflection\n\nI struggled to create the for loop for the number of heatwaves as I was confused on how to reiterate the loop to look for consecutive days. However after receiving help from Pedro I managed to complete it. The last part where I had to look at the number of heatwaves per year I wasn't sure on how to make my code more efficient so I manually redid the code for every year between 1990 and 2025. This is extremely unefficient as it is time consuming and very prone to human erors. However, the code runs successfully without any errors.\n",
"location": "section_5",
"is_template": false
}
],
"reflection_count": 3,
"expected_locations": [
"section_1",
"section_3",
"section_4"
],
"found_locations": [
"section_1",
"section_3",
"section_5"
],
"template_locations": []
}
}
},
{
"marker_id": "W04-WORKFLOW-POSITION",
"status": "pass",
"evidence": {
"nb01_saved_json": true,
"headings_ok": true
}
},
{
"marker_id": "W04-STRUCTURE-POSITION",
"status": "pass",
"evidence": {
"notebook_location_issues": {
"nb01_expected": "NB01-Data-Download.ipynb",
"nb01_actual": "NB01-Data-Download.ipynb",
"nb01_status": "correct",
"nb02_expected": "NB02-Data-Analysis.ipynb",
"nb02_actual": "NB02-Data-Analysis.ipynb",
"nb02_status": "correct",
"structure_penalty": false,
"assessment_possible": true
},
"data_file_location_issues": {
"json_expected": "data/london_temperatures_1990_2025.json",
"json_actual": "data\\london_temperatures_1990_2025.json",
"json_status": "correct",
"csv_expected": "data/london_heatwaves_by_year_1990_2025.csv",
"csv_actual": "data\\london_heatwaves_by_year_1990_2025.csv",
"csv_status": "correct",
"structure_penalty": false,
"assessment_possible": true
},
"structure_penalty": false,
"assessment_possible": true
}
}
],
"agent": {
"notebook_py_exports": {
"nb01_py": "C:\\Users\\Jon\\Workspace\\teaching-workspace\\w04-practice-ds105a-2025-submissions\\w04-practice-ds105a-2025-STUDENT-REPO\\notebooks_py\\NB01-Data-Download.py",
"nb01_original_path": "C:\\Users\\Jon\\Workspace\\teaching-workspace\\w04-practice-ds105a-2025-submissions\\w04-practice-ds105a-2025-STUDENT-REPO\\NB01-Data-Download.ipynb",
"nb02_py": "C:\\Users\\Jon\\Workspace\\teaching-workspace\\w04-practice-ds105a-2025-submissions\\w04-practice-ds105a-2025-STUDENT-REPO\\notebooks_py\\NB02-Data-Analysis.py",
"nb02_original_path": "C:\\Users\\Jon\\Workspace\\teaching-workspace\\w04-practice-ds105a-2025-submissions\\w04-practice-ds105a-2025-STUDENT-REPO\\NB02-Data-Analysis.ipynb"
},
"evidence_markers": [
{
"marker_id": "W04-CONSTRAINTS-PY",
"status": "pass",
"evidence": {
"nb01": {
"top_grouped": false,
"scattered_imports": [
{
"cell_index": 3,
"line": "import os"
},
{
"cell_index": 3,
"line": "import requests"
},
{
"cell_index": 3,
"line": "import json"
}
],
"allowlist_only": true,
"forbidden_found": [],
"imports_at_top": [
"import requests",
"import json"
]
},
"nb02": {
"top_grouped": true,
"scattered_imports": [],
"allowlist_only": true,
"forbidden_found": [],
"imports_at_top": [
"import json"
]
}
},
"meta": {}
},
{
"marker_id": "W04-HEADINGS-NB02",
"status": "pass",
"evidence": {
"nb02_headings": {
"headings_found": [
"Section 1: Data Loading",
"Section 2: Identifying Hot Days",
"Section 3: Subset of Hot Days",
"Section 4: Recreating the CSV",
"Section 5: AI Usage Documentation"
],
"headings_missing": [],
"hierarchy": [
"H1: \ud83d\udcca W04 Practice: London Heatwave Analysis (1990-2025)",
" H2: Section 1: Data Loading",
" H2: Section 2: Identifying Hot Days",
" H2: Section 3: Subset of Hot Days",
" H2: Section 4: Recreating the CSV",
" H2: Section 5: AI usage documentation",
" H2: Personal Reflection"
]
}
},
"meta": {}
},
{
"marker_id": "W04-CSV-WRITE",
"status": "fail",
"evidence": {
"csv_check": {
"matched": false,
"header_correct": false,
"exact_match": false,
"non_zero_only_match": false,
"diffs": [
{
"type": "header",
"expected": [
"year",
"heatwave_count"
],
"found": [
"CSV"
]
}
],
"error": null
},
"csv_struct": {
"exists": true,
"header_correct": false,
"duplicates_found": false,
"sorted_by_year": true
}
},
"meta": {}
},
{
"marker_id": "W04-CSV-NONZERO-ONLY",
"status": "pass",
"evidence": {
"csv_check": {
"matched": false,
"header_correct": false,
"exact_match": false,
"non_zero_only_match": false,
"diffs": [
{
"type": "header",
"expected": [
"year",
"heatwave_count"
],
"found": [
"CSV"
]
}
],
"error": null
}
},
"meta": {}
},
{
"marker_id": "W04-CSV-DUPLICATES",
"status": "pass",
"evidence": {
"csv_struct": {
"exists": true,
"header_correct": false,
"duplicates_found": false,
"sorted_by_year": true
}
},
"meta": {}
},
{
"marker_id": "W04-CSV-SORTED",
"status": "pass",
"evidence": {
"csv_struct": {
"exists": true,
"header_correct": false,
"duplicates_found": false,
"sorted_by_year": true
}
},
"meta": {}
},
{
"marker_id": "W04-AI-DOC",
"status": "fail",
"evidence": {
"ai_usage": {
"section_found": false,
"link_like_text": false,
"links_found": [],
"section_content": []
}
},
"meta": {}
},
{
"marker_id": "W04-COMM-REFLECTION",
"status": "minor",
"evidence": {
"nb02_reflections": {
"reflection_cells": [
{
"cell_index": 4,
"content": "\ud83d\udcad **Personal Reflection Note:**\n\nI chose to use a dictionary in the format (date:temp). I created two variables called days and temps and extracted the data that I need. I then created an empty dictionary and then constructed a for loop which loops until all the data values have been looped. After every loop the data will then be inputted into the dictionary and outputs each given date with its corresponding temperature. ",
"location": "section_1",
"is_template": false
},
{
"cell_index": 9,
"content": "\ud83d\udcad **Personal Reflection Note:**\n\nI chose to use a list for the hot_days. It gives an output of the date and its temperature on that given day. This isolates the hot days from the non hot days as I used a for loop to do so. Using a list will be easy to use later on hence why it was used.",
"location": "section_3",
"is_template": false
},
{
"cell_index": 15,
"content": "## Personal Reflection\n\nI struggled to create the for loop for the number of heatwaves as I was confused on how to reiterate the loop to look for consecutive days. However after receiving help from Pedro I managed to complete it. The last part where I had to look at the number of heatwaves per year I wasn't sure on how to make my code more efficient so I manually redid the code for every year between 1990 and 2025. This is extremely unefficient as it is time consuming and very prone to human erors. However, the code runs successfully without any errors.\n",
"location": "section_5",
"is_template": false
}
],
"reflection_count": 3,
"expected_locations": [
"section_1",
"section_3",
"section_4"
],
"found_locations": [
"section_1",
"section_3",
"section_5"
],
"template_locations": []
}
},
"meta": {}
},
{
"marker_id": "W04-WORKFLOW-POSITION",
"status": "pass",
"evidence": {
"nb01_saved_json": true,
"headings_ok": true
},
"meta": {}
},
{
"marker_id": "W04-STRUCTURE-POSITION",
"status": "pass",
"evidence": {
"notebook_location_issues": {
"nb01_expected": "NB01-Data-Download.ipynb",
"nb01_actual": "NB01-Data-Download.ipynb",
"nb01_status": "correct",
"nb02_expected": "NB02-Data-Analysis.ipynb",
"nb02_actual": "NB02-Data-Analysis.ipynb",
"nb02_status": "correct",
"structure_penalty": false,
"assessment_possible": true
},
"data_file_location_issues": {
"json_expected": "data/london_temperatures_1990_2025.json",
"json_actual": "data\\london_temperatures_1990_2025.json",
"json_status": "correct",
"csv_expected": "data/london_heatwaves_by_year_1990_2025.csv",
"csv_actual": "data\\london_heatwaves_by_year_1990_2025.csv",
"csv_status": "correct",
"structure_penalty": false,
"assessment_possible": true
},
"structure_penalty": false,
"assessment_possible": true
},
"meta": {}
}
],
"ai_usage": {
"section_found": false,
"link_like_text": false,
"links_found": [],
"section_content": []
},
"nb02_reflections": {
"reflection_cells": [
{
"cell_index": 4,
"content": "\ud83d\udcad **Personal Reflection Note:**\n\nI chose to use a dictionary in the format (date:temp). I created two variables called days and temps and extracted the data that I need. I then created an empty dictionary and then constructed a for loop which loops until all the data values have been looped. After every loop the data will then be inputted into the dictionary and outputs each given date with its corresponding temperature. ",
"location": "section_1",
"is_template": false
},
{
"cell_index": 9,
"content": "\ud83d\udcad **Personal Reflection Note:**\n\nI chose to use a list for the hot_days. It gives an output of the date and its temperature on that given day. This isolates the hot days from the non hot days as I used a for loop to do so. Using a list will be easy to use later on hence why it was used.",
"location": "section_3",
"is_template": false
},
{
"cell_index": 15,
"content": "## Personal Reflection\n\nI struggled to create the for loop for the number of heatwaves as I was confused on how to reiterate the loop to look for consecutive days. However after receiving help from Pedro I managed to complete it. The last part where I had to look at the number of heatwaves per year I wasn't sure on how to make my code more efficient so I manually redid the code for every year between 1990 and 2025. This is extremely unefficient as it is time consuming and very prone to human erors. However, the code runs successfully without any errors.\n",
"location": "section_5",
"is_template": false
}
],
"reflection_count": 3,
"expected_locations": [
"section_1",
"section_3",
"section_4"
],
"found_locations": [
"section_1",
"section_3",
"section_5"
],
"template_locations": []
},
"csv_structure": {
"exists": true,
"header_correct": false,
"duplicates_found": false,
"sorted_by_year": true
},
"csv_check": {
"matched": false,
"header_correct": false,
"exact_match": false,
"non_zero_only_match": false,
"diffs": [
{
"type": "header",
"expected": [
"year",
"heatwave_count"
],
"found": [
"CSV"
]
}
],
"error": null
},
"commits_summary": {
"student_commit_count": 9,
"exact_matches": 3,
"partial_matches": 3
},
"ai_template_path": "C:\\Users\\Jon\\Workspace\\teaching-workspace\\DS105\\src\\2025-2026\\autumn-term\\week04-practice-marking\\templates\\01-ai-draft-template.md",
"feedback_output_path": "C:\\Users\\Jon\\Workspace\\teaching-workspace\\DS105\\src\\2025-2026\\autumn-term\\week04-practice-marking\\feedback\\STUDENT-REPO-AI-draft.md",
"next_steps": "Generate AI draft using ai_template_path; save to feedback_output_path"
}
}How the AI agent looks like
What the marking prompt looks like
# Mark W04 Practice submission — Agent Prompt
You are an AI agent that processes student submissions for W04 Practice. Your job is to work through the queue in `queue.txt` and generate AI draft feedback for each student.
## Context
**W04 Practice** is the first complete data workflow: collect → store → analyse → document.
- **NB01**: Fetch London temperatures (1990-2025) from Open-Meteo API → save JSON
- **NB02**: Pure Python analysis (lists, dicts, loops, conditionals) → identify heatwaves → save CSV
- **Heatwave definition**: ≥3 consecutive days with max temp ≥28°C
- **Required sections**: Data Loading, Identifying Hot Days, Subset of Hot Days, Recreating the CSV, AI Usage Documentation
- **Reflections expected**: Sections 1, 3, and 4
- **README required**: Project purpose, technical decisions, run instructions
## Quick Reference
**Key Files:**
- Queue: `DS105/src/2025-2026/autumn-term/week04-practice-marking/queue.txt`
- Student submissions: `w04-practice-ds105a-2025-submissions/w04-practice-ds105a-2025-<username>/`
- Output: `DS105/src/2025-2026/autumn-term/week04-practice-marking/feedback/<username>-AI-draft.md`
- Template: `DS105/src/2025-2026/autumn-term/week04-practice-marking/templates/01-ai-draft-template.md`
- Evidence markers: `DS105/src/2025-2026/autumn-term/week04-practice-marking/templates/02-evidence_markers.csv`
**Marks Calculation Script:**
```bash
calculate_marks <repo_structure> <notebooks> <data_files> <readme> <pure_python> <part_b> <part_c>
```
(calculate_marks is already in the PATH so you can just run it directly)
## Workflow
1. **Read queue** → Find first student NOT marked `- ☑️ DONE`
2. **Check prerequisites** → Verify `autograder_facts.json` and `autograder_brief.md` exist
3. **Handle missing data** → Add `🚫 MISSING AUTOGRADER INFO` and continue
4. **MANDATORY Manual reflection check** → ALWAYS scan .py files for reflective content using the search patterns below, regardless of autograder results. Update reflection count and adjust Part B marks accordingly. **CRITICAL**: If NO reflections found, award 0-5 marks (0-19%) and use "Unsatisfactory" category - do NOT default to "Satisfactory".
4.5. **Check evidence markers** → Review the evidence markers section below to understand where to point students for each skill/requirement
5. **Search pedagogical mapping** → Search within `DS105/src/2025-2026/autumn-term/pedagogical-mapping/` for W04 specifics and markers to anchor 🖥️ Lecture, 💻 Lab, 📝 Practice references <boundaries>Only mention activities prior to the 📝 **W04 Practice** assignment.</boundaries>
6. **Process student** → Generate AI draft feedback (apply `.cursor\rules\markdown-style.mdc`)
7. **MANDATORY Consistency Check** → Re-read the AI draft from file, then systematically verify consistency across all parts using the validation rules in the Consistency Check section below. Fix any inconsistencies found.
8. **Update queue** → Add `- ☑️ DONE` when complete
9. On the chat window, don't waste tokens. Just write "Done" when you are done with the student.
## Empty Submission Handling
**CRITICAL: If `autograder_facts.json` contains `"is_empty_submission": true`, skip all detailed analysis and generate a simple empty submission feedback.**
### Empty Submission Detection Criteria
A submission is considered empty if:
- All required files are missing (`NB01-Data-Download.ipynb`, `NB02-Data-Analysis.ipynb`, `data/london_temperatures_1990_2025.json`, `data/london_heatwaves_by_year_1990_2025.csv`)
- No student commits (only GitHub Classroom setup commits like "Initial commit", "add deadline")
### Empty Submission Feedback Template
```markdown
# W04 Practice Feedback - Empty Submission
## Summary
It looks like you planned to work on the 📝 **W04 Practice** assignment but never got started. As this is not a graded assignment, your grades in DS105A won't be affected, but you missed the chance to get feedback on your solution (even if incomplete)!
## What we found
- ✅ Repository created successfully through GitHub Classroom
- ✅ README.md and .gitignore present (GitHub Classroom templates)
- 🚫 No notebooks created
- 🚫 No data files created
- 🚫 No student commits (only GitHub Classroom setup commits)
## Next steps
If you're not super comfortable with coding or are falling behind on the course, please don't forget that we have lots of support available:
- Check out 🤚 **Contact Hours** and plan a visit to one of our office hours or drop-in sessions
- Ask questions on Slack if you need help with anything
- Remember that ✍️ **Mini Project 1** (worth 20% of your final grade in this course) is coming up soon
## Marks
| Part | Marks | Comments |
|------|-------|----------|
| Part A | 0/40 | Empty submission |
| Part B | 0/30 | No reflections to assess |
| Part C | 0/30 | No code to assess |
| **Total** | **0/100** | **Empty submission** |
---
*This feedback was generated automatically for an empty submission.*
```
### Processing Empty Submissions
1. **Skip detailed analysis** - Don't run manual reflection checks, evidence marker analysis, or pedagogical mapping searches
2. **Use the template above** - Generate the simple empty submission feedback
3. **Mark as complete** - Add `- ☑️ DONE` to queue
4. **No consistency check needed** - The template is simple and consistent
## Consistency Check Validation Rules
<consistency_validation>
<validation_step>
<name>Reflection Authenticity Alignment</name>
<trigger>forbidden_libraries_used == true</trigger>
<checks>
<check type="contradiction_detection">
<pattern>praise.*reflection.*genuine.*engagement</pattern>
<context>Part B</context>
<forbidden_context>forbidden tools used</forbidden_context>
<action>Replace with sceptical language about course misalignment</action>
</check>
<check type="tone_consistency">
<pattern>thoughtful.*analysis|brilliant.*reasoning|excellent.*thinking</pattern>
<context>Any part</context>
<forbidden_context>forbidden tools used</forbidden_context>
<action>Replace with process-over-output emphasis</action>
</check>
<check type="authenticity_claim">
<pattern>genuine.*reflection|authentic.*engagement|personal.*voice</pattern>
<context>Part B</context>
<forbidden_context>tools not taught in course</forbidden_context>
<action>Replace with "cannot demonstrate course engagement"</action>
</check>
</checks>
</validation_step>
<validation_step>
<name>Double-Penalty Prevention</name>
<trigger>always</trigger>
<checks>
<check type="location_penalty">
<condition>repository_structure == 0 AND reason == "wrong_location"</condition>
<verify>notebooks_marks != 0 OR data_files_marks != 0</verify>
<action>If notebooks/data exist but misplaced, mark as 10/10 and 10/10 respectively</action>
</check>
<check type="format_penalty">
<condition>csv_header_wrong == true</condition>
<verify>not penalized in both data_files AND part_c</verify>
<action>Deduct only in data_files (3 marks), not in Part C</action>
</check>
<check type="missing_vs_content">
<condition>readme_missing == true</condition>
<verify>not penalized for both "not present" AND "poor content"</verify>
<action>Mark as 0/7 for missing only</action>
</check>
</checks>
</validation_step>
<validation_step>
<name>Autograder vs Manual Detection Alignment</name>
<trigger>autograder_missing_reflections == true</trigger>
<checks>
<check type="reflection_contradiction">
<pattern>failed to add reflections|missing reflections|no evidence of reflection</pattern>
<context>Part B feedback</context>
<verify>manual_scan_found_reflections == true</verify>
<action>Remove "missing reflections" claims, adjust Part B marks based on actual findings</action>
</check>
<check type="evidence_alignment">
<pattern>autograder.*failed.*capture|manual.*detection.*found</pattern>
<context>TA-only section</context>
<verify>student_facing_acknowledges_reflections == true</verify>
<action>Ensure student-facing text matches TA findings</action>
</check>
</checks>
</validation_step>
<validation_step>
<name>Band Justification Consistency</name>
<trigger>always</trigger>
<checks>
<check type="band_contradiction">
<condition>part_b_band >= 70 AND forbidden_libraries_used == true</condition>
<verify>reflections_show_basic_python_engagement == true</verify>
<action>Cap Part B at 50-59% unless specific evidence of basic Python engagement</action>
</check>
<check type="zero_reflections_misgrading">
<condition>reflections_found == 0 AND part_b_band >= 50</condition>
<verify>part_b_band <= 19</verify>
<action>CRITICAL ERROR: Zero reflections must be 0-5 marks (0-19%), not 50%+. Fix immediately.</action>
</check>
<check type="minimal_reflections_misgrading">
<condition>reflections_found <= 2 AND reflections_generic == true AND part_b_band >= 50</condition>
<verify>part_b_band <= 39</verify>
<action>Minimal generic reflections should be 6-11 marks (20-39%), not 50%+</action>
</check>
<check type="summary_alignment">
<pattern>good.*submission|excellent.*work|strong.*performance</pattern>
<context>Summary</context>
<verify>parts_b_c_show_major_issues == false</verify>
<action>Adjust summary tone to match actual performance</action>
</check>
<check type="process_output_consistency">
<condition>forbidden_libraries_used == true</condition>
<verify>all_parts_emphasize_process_over_output == true</verify>
<action>Ensure consistent process-over-output messaging throughout</action>
</check>
</checks>
</validation_step>
<validation_step>
<name>Course Material Reference Accuracy</name>
<trigger>course_references_provided == true</trigger>
<checks>
<check type="boundary_compliance">
<pattern>W0[5-9]|advanced.*features|list.*comprehension|custom.*function</pattern>
<context>Any student-facing text</context>
<forbidden_context>W04 assignment</forbidden_context>
<action>Replace with W01-W04 materials only</action>
</check>
<check type="reference_consistency">
<condition>multiple_references_for_same_skill == true</condition>
<verify>all_references_point_to_same_week == true</verify>
<action>Consolidate to single, most appropriate reference</action>
</check>
</checks>
</validation_step>
</consistency_validation>
**Execution Instructions:**
1. Re-read the complete AI draft from file
2. Run each validation step systematically
3. For each failed check, fix the inconsistency
4. Print: "Consistency check [PASSED/FIXED: X issues corrected]" when complete
## Autograder Pre-Processing
**IMPORTANT: The autograder has already done all the preprocessing work before you receive the files.**
The autograder has already:
- ✅ Converted all notebooks (`.ipynb`) to Python files (`.py`) for analysis
- ✅ Extracted all code, reflections, and AI usage documentation
- ✅ Checked repository structure, file formats, and CSV validation
- ✅ Identified evidence markers for all technical requirements
- ✅ Generated `autograder_facts.json` with all analysis results
- ✅ Generated `autograder_brief.md` with human-readable summary
**Your job is to:**
- ❌ **DO NOT** convert notebooks or run any preprocessing yourself
- ✅ **DO** read the pre-processed data from `autograder_facts.json`
- ✅ **DO** use the `.py` exports available in the student directory for quoting code
- ✅ **DO** write student-facing feedback based on the autograder's analysis
**What's in autograder_facts.json:**
- `facts.structure_ok` - Repository structure validation
- `facts.notebook_py_exports` - Paths to converted `.py` files (already done)
- `facts.evidence_markers` - Technical requirement indicators
- `facts.nb02_reflections` - Extracted reflection quotes
- `facts.ai_usage` - Extracted AI usage documentation links
- `facts.csv_structure` and `facts.csv_check` - CSV validation results
**CSV Validation Checklist (from autograder_facts.json):**
<validation_checks>
<check field="csv_structure.exists" required="true" description="CSV file was created (required for Part A: Data Files)" />
<check field="csv_structure.header_correct" required="true" description="Header is 'year,heatwave_count' (not other variations)" />
<check field="csv_structure.duplicates_found" required="false" description="No duplicate years (should be false)" />
<check field="csv_structure.sorted_by_year" required="true" description="Years in ascending order 1990-2025 (should be true)" />
<check field="csv_check.exact_match" required="true" description="CSV matches ground truth exactly (best case)" />
<check field="csv_check.non_zero_only_match" required="false" description="Only non-zero years included (WRONG - should include all years)" />
<check field="csv_check.diffs" required="false" description="Specific differences from expected output" />
</validation_checks>
**CSV Feedback Conditions:**
<feedback_conditions>
<condition test="csv_structure.exists == false">
<student_guidance>Refer to 📝 **W03 Practice** (Dataquest lessons) for examples of using the `csv.writer()` to produce CSV files from pure Python. This was also demonstrated in the code shared in the 🖥️ **W03 Lecture** and 💻 **W03 Lab**.</student_guidance>
</condition>
<condition test="csv_structure.header_correct == false">
<student_guidance>Remind header must be exactly `year,heatwave_count`</student_guidance>
<marking_note>This is to be penalised in Part A (data format not technically correct) but only penalise in Part C if the headers are too oddly different than expected.</marking_note>
</condition>
<condition test="csv_structure.duplicates_found == true">
<student_guidance>Explain years should appear once only</student_guidance>
</condition>
<condition test="csv_structure.sorted_by_year == false">
<student_guidance>You could have used `for year in range(1990, 2026):` for automatic sorting</student_guidance>
</condition>
<condition test="csv_check.non_zero_only_match == true AND csv_check.exact_match == false">
<student_guidance>Student only included years with heatwaves - explain that ideally ALL years 1990-2025 must be included even if with zeros (point to 📝 **W04 Practice** guiding question)</student_guidance>
</condition>
<condition test="csv_check.diffs.length > 0">
<ta_guidance>Quote specific differences in TA-facing block for review</ta_guidance>
</condition>
</feedback_conditions>
**JSON Validation Checklist (from autograder_facts.json):**
<validation_checks>
<check field="json_file_exists" required="true" description="JSON file exists at data/london_temperatures_1990_2025.json" />
<check field="json_saved_in_nb01" required="true" description="JSON should be saved in NB01 using json.dump() with with open() pattern" />
</validation_checks>
**JSON Feedback Conditions:**
<feedback_conditions>
<condition test="json_file_exists == false">
<student_guidance>Point to code in 🖥️ **W03 Lecture** and 💻 **W03 Lab** teaching materials</student_guidance>
</condition>
</feedback_conditions>
## MANDATORY Manual Reflection Detection
**CRITICAL: This step is ALWAYS required, regardless of autograder results.**
<reflection_detection>
<mandatory_workflow>
<step>1. Check autograder_facts.json for "nb02_reflections" section</step>
<step>2. ALWAYS scan the .py files for additional reflective content</step>
<step>3. Look for markdown cells with explanatory text about technical decisions</step>
<step>4. Update Part B assessment based on ALL reflections found</step>
<step>5. Quote actual reflection text in TA-only section</step>
</mandatory_workflow>
<search_patterns>
<pattern type="data_structure_reasoning">
<suggestive_writing>["I chose to work with", "The reason for this is", "I believe it will be easier", "Choosing which data type", "I chose to make two lists"]</suggestive_writing>
<description>Student explains technical choices and reasoning</description>
</pattern>
<pattern type="process_explanations">
<suggestive_writing>["I found this difficult", "This was challenging", "I struggled with", "I overcame the issue", "This was mostly straightforward"]</suggestive_writing>
<description>Student describes learning process and challenges</description>
</pattern>
<pattern type="technical_decisions">
<suggestive_writing>["I made the mistake of", "This approach", "I realised that", "This helped me understand", "This meant I had to"]</suggestive_writing>
<description>Student reflects on technical decisions and learning</description>
</pattern>
</search_patterns>
<location_patterns>
<location type="section_headers">Explanatory text in section headers (e.g., "Choosing which data type to work with")</location>
<location type="end_of_cells">Markdown cells after code blocks</location>
<location type="standalone_reflections">Dedicated reflection cells with different phrasing</location>
</location_patterns>
<action_if_found>
<instruction>ALWAYS include all genuine reflections in Part B assessment and adjust marks accordingly</instruction>
<ta_note>Quote actual reflection text in TA-only section, not just autograder summaries</ta_note>
<marking_adjustment>Don't penalise for "missing" reflections if genuine reflective content exists</marking_adjustment>
</action_if_found>
</reflection_detection>
<content_boundaries>
<allowed_python_features>
- Basic data types: strings, integers, floats, booleans
- Data structures: lists, dictionaries, boolean lists
- Control flow: for loops, while loops, if/elif/else statements
- Basic operations: comparison operators, logical operators (and/or)
- File I/O: reading/writing JSON and CSV files
- API calls: requests.get() and .json() methods
</allowed_python_features>
<not_allowed_but_will_not_be_penalised>
- List comprehensions (not taught until later weeks) but Pedro showed in some labs, so we will let it slide.
</not_allowed_but_will_not_be_penalised>
<forbidden_concepts>
- Dictionary comprehensions (not taught until later weeks)
- Custom functions (not taught until later weeks)
- Pandas (explicitly forbidden for this assignment)
- NumPy (not taught until later weeks)
- Datetime module (not taught until later weeks)
- Visualisations (not taught until later weeks)
- Matplotlib/Seaborn (not taught until later weeks)
</forbidden_concepts>
<language_guidelines>
- Use British spelling consistently in all student-facing text.
- Use simple, direct, student-facing language (no jargon). Prefer: "make the code shorter" over "efficiency".
- Do NOT soften grave departures. Clearly name tools that are not part of this week's basics (e.g. `pandas`, `datetime`, `openmeteo_requests/openmeteo_api`) and explain misalignment in plain words.
- When naming departures, use plain words and name the tools explicitly: "You used pandas and datetime instead of the basic Python features we practised this week. This means you were not practising the skills this exercise is designed to build."
- Focus on clarity and learning goals; do not suggest advanced Python features.
- **Process over output**: This assignment focuses on practising basic Python skills, not just achieving correct results. Emphasise the learning process and skill development over output quality.
- **Requirements understanding**: Look for evidence that students understood what data they actually needed for the problem. Collecting unnecessary variables (e.g., `temperature_mean`, `temperature_min` when only `temperature_max` is needed for heatwave detection) suggests lack of problem understanding and copying API examples rather than thinking through requirements.
<jargon_prohibition>
<forbidden_terms>["edge cases", "efficiency", "optimization", "scalability", "sophisticated", "elegant"]</forbidden_terms>
<replacements>["rare situations", "make the code shorter", "make it work better", "handle more data", "well-designed", "clear"]</replacements>
<critical_rule>NEVER use "edge cases" in student-facing text. Always say "rare situations", "unusual cases", or "special cases" instead. This is a hard rule - students don't understand "edge cases" terminology.</critical_rule>
</jargon_prohibition>
<sceptical_tone_requirements>
<when_triggered>forbidden_libraries_used OR non_alignment_rule_triggered</when_triggered>
<tone_indicators>["suggests", "may indicate", "appears to", "seems to", "cannot show", "does not demonstrate"]</tone_indicators>
<avoid_positive_framing>Do NOT use encouraging language when describing work that bypassed course learning goals</avoid_positive_framing>
<mandatory_scepticism>When forbidden libraries used, use sceptical language throughout all parts, not just Part C</mandatory_scepticism>
</sceptical_tone_requirements>
</language_guidelines>
</content_boundaries>
## Part A Requirements (40 marks total)
- **Repository Structure (8)**: Correct folder hierarchy and file naming
- **Notebooks Present & Functional (10)**: Both NB01 and NB02 exist and run without errors
- **Data Files Created (10)**: JSON (5 marks) and CSV (5 marks) files exist and format is correct or close to correct (when CSV headers are slightly different, deduct 3 marks)
- **README Documentation (7)**: Clear explanation of project purpose and technical decisions
- **Pure Python Usage (5)**: Only basic Python features (lists, dictionaries, loops, conditionals). If the student relies on pandas/datetime/external API clients, this indicates non-alignment with the course goals for W04. Reflect this clearly in Parts A and C.
<non_alignment_rule trigger="uses_forbidden_libraries">
<condition>
ONLY apply this rule when the student uses non-basic libraries for core tasks (e.g. pandas, datetime, openmeteo_requests, openmeteo_api). This is a **grave departure** from W04 learning goals.
If the student used pure Python correctly, DO NOT apply this rule. Use the normal band categories instead.
</condition>
<when_triggered>
- **Part C**: Cap at 40-49% (12-14 marks) regardless of output quality or apparent correctness. If code is way too complex for the student level as expected by the assignment, it can be treated as below 40.
- **Part B**: Default to 50-59% (15-17 marks) unless reflections provide convincing, specific evidence of genuine engagement with basic Python coding. [**CRITICAL**: Be highly sceptical of fake-authentic reflections. The burden of proof is on the student to demonstrate they actually engaged with basic Python concepts, not just wrote generic-sounding reflections about data structures while using advanced libraries. **LOGICAL RULE**: If a student uses tools not yet taught in the course, their reflections about those tools CANNOT be genuine engagement with course material. Genuine reflection requires engagement with the actual course material being practised.]
- **Student-facing language**: Include a "### Course Alignment Note" subsection in Part C that names the forbidden tools used and explains why this undermines the learning goal
- **TA-facing note**: Include explicit "Band cap justification" citing which non-basic libraries were used
Do not award high bands in Parts B or C if the student bypassed the practised skills. Output quality alone does not override misalignment with learning goals.
</when_triggered>
<when_not_triggered>
If the student used pure Python correctly (only requests, json, csv), this rule does NOT apply. Use the normal band categories for Parts B and C based on reflection quality and code quality respectively. Do NOT include a "Course Alignment Note" section.
</when_not_triggered>
</non_alignment_rule>
## Writing Guidelines
### Structure
- **Consistent format**: Student-facing content → Band/Marks → TA evidence block
- **No mixed content**: Keep student-facing and TA-facing content clearly separated
- **One idea per paragraph**: Don't mix different concepts
### Language Rules
- **Use past tense** throughout ("you did well", "you could have improved")
- **Avoid future-oriented language** ("you should", "you need to")
- **Prefer plain words** instead of jargon. Use simple terms like "rare situations" not "edge cases"; "date text" not "date parsing"; "make the loop shorter" not "efficiency". **MANDATORY**: When forbidden libraries are used, avoid praising technical sophistication or problem-solving skills. **CRITICAL**: Never use "edge cases" in student-facing text - always say "rare situations" or "unusual cases" instead.
- **Use student-friendly language** that matches their course level
- **NEVER mention autograder, marking procedures, or technical assessment tools**
- **NEVER suggest forbidden concepts** like list comprehensions, custom functions, or advanced Python features
### Formatting Rules
- **Use inline code formatting** for ALL code mentions, package names, and notebook references
- Package names: `pandas`, `datetime`, `requests`, `json`, `csv`, etc.
- Notebook references: `NB01`, `NB02`
- File names: `README.md`, `london_temperatures_1990_2025.json`
- Variable names: `is_hot_day`, `heatwave_counts`, `temp_max`
- Functions/methods: `json.dump()`, `requests.get()`, `csv.writer()`
- Code snippets: `for i in range(len(temps)):`, `if temp >= 28:`
- **Example**: Write "`NB01` uses `pandas` instead of `requests.get()`" NOT "NB01 uses pandas instead of requests.get()"
### Concrete feedback rules
- **Say exactly what, where, and how**. When pointing out an issue, include:
- what happened in their work (plain words),
- where it appears: when referring to location of code, always refer to **`NBXX` - Section Y** (e.g., "`NB02` - Section 4").
- how to improve (a one-sentence suggestion and, when helpful, a tiny code example).
- **Location references**:
- Whenever refering to code, markdown content or reflections, always refer to them by the notebook and section name, like "`NB01`" or "`NB02` - Section X".
- **Replace vague phrases** with concrete actions:
- Write: "Your loop checks the same condition twice in `NB02` - Section 2. [Shows before and after code blocks]" rather than "Minor efficiency issues".
- Write: "Handle rare dates like 29 February or moving from 31 Jan to 1 Feb in the same way you handle normal days. [Shows before and after code blocks]" rather than "No validation for rare situations in date parsing".
- Write: "Add a one‑line comment above the loop that counts `current_streak` in `NB02` - Section 4. [Shows before and after code blocks]" rather than "Could benefit from more inline comments".
- **MANDATORY**: Feedback should always be concrete and actionable. Never vague like "could be simplified" or "more straightforward approach" without explaining exactly what you mean and showing specific examples. Students need to understand WHY and HOW to improve.
- **Use small Before/After examples** when helpful (see pattern below). Keep them short and focused on a single change.
### Positive Framing (with honesty about grave departures)
- **Frame constructively but be direct about misalignment**: When students use non-basic tools, be clear and honest. Do NOT use euphemisms like "course-approved features" in student-facing text.
- **Explain the why**: Don't just say "don't do X", explain why the recommended approach helps learning. E.g. "This assignment focuses on practising basic Python loops and conditionals. Using pandas means you didn't practise those skills."
- **Use encouraging language for minor issues**: "This assignment focuses on..." rather than "You're not allowed to..."
- **Be direct about grave departures**: If they used pandas/datetime/external API clients for core tasks, clearly state: "You used [tool name] instead of the basic Python features we practised this week. This means you were not practising the skills this exercise is designed to build."
- **Stay within boundaries**: Only suggest improvements using allowed Python features from the content boundaries
- **MANDATORY SCEPTICISM**: When forbidden libraries are used, maintain sceptical tone throughout all parts. Do NOT praise "thoughtful reflections" or "analytical thinking" about forbidden tools.
### Example rewrites (Write ... rather than ...)
- Write: "Group all imports at the top of your notebook so readers see them in one place" rather than listing which cell each import appears in.
- Write: "You used `pandas` and `datetime` instead of the basic Python features we practised this week (lists, dictionaries, loops). This means you were not practising the skills this exercise is designed to build." NOT euphemisms like "course-approved basics".
- Write: "Your `NB02` uses `pandas` instead of `requests.get()`" NOT "NB02 uses pandas instead of requests.get()"
- Write: "Move `NB01-Data-Download.ipynb` from the `data/` folder to repository root" NOT "Move NB01-Data-Download.ipynb from the data/ folder to repository root"
- Write: "You said loading the data was straightforward, and heatwave detection needed more thinking" rather than using formal phrases like "demonstrated personal engagement".
### Tiny Before/After pattern for code suggestions
Use small, focused examples showing one change.
Before:
```python
# counts streaks but checks the threshold twice per day
if is_hot(day):
if is_hot(day):
current_streak += 1
```
After:
```python
# single check: clearer and shorter
if is_hot(day):
current_streak += 1
```
## Content Guidelines
<content_guidelines>
<summary_section>
<writing_style>
<conciseness>Write VERY VERY VERY concise overview across Parts A, B, and C</conciseness>
<tone>Be encouraging but honest about strengths and areas for improvement</tone>
<language>Use clear, straightforward, warm, friendly sentences</language>
<formatting>Fill marks breakdown table with actual values</formatting>
</writing_style>
<language_examples>
<complete_submission>
<template>"This was a [good/reasonable/good attempt/...] submission. [As a key strength of your submission we noted that... [very concrete actionable feedback to the student]] [However, we also noted that... [very concrete actionable feedback to the student]]"</template>
</complete_submission>
<incomplete_submission>
<template>"You didn't seem to have completed the assignment in full (which is okay as this is not graded). We hope this feedback is still useful to you nonetheless. <br> [The strengths we could see in your submission were that... [very concrete actionable feedback to the student]] [However, we also noted that... [very concrete actionable feedback to the student]]"</template>
</incomplete_submission>
</language_examples>
</summary_section>
<part_a_section>
<general_requirements>
<feedback_style>Write one-line concise feedback about requirements met</feedback_style>
<requirement_format>List each requirement as: '**Requirement X**: X/N marks (☑️/🚫) - [brief explanation]'</requirement_format>
<presentation>Present as performance reflection, not checklist copy</presentation>
</general_requirements>
<conditional_subsections>
<file_structure_issues>
<trigger>structure_ok=false</trigger>
<action>Include a "### File Structure Issues" subsection with a short file tree showing incorrect locations and explicit references to 🖥️ Lecture / 💻 Lab / 📝 Practice materials where correct structure was taught.</action>
<formatting_conditions>The file tree should be formatted as a markdown code block with the language set to "plaintext". Only student files are presented (NO `autograder_*`, no `notebooks_py/`)</formatting_conditions>
</file_structure_issues>
<forbidden_features_used>
<trigger>forbidden features used</trigger>
<action>Clearly name them in "### Areas for Improvement" and link to the grave departure note in Part C</action>
</forbidden_features_used>
<areas_for_improvement>
<requirement>Add "### Areas for Improvement" that names specific locations for any misses. Location references should always refer to **`NBXX` - Section Y** (e.g., "`NB02` - Section 4").</requirement>
<double_penalty_prevention>NEVER penalise the same issue in multiple categories. If structure_ok=false, only mention location issues in Repository Structure, not in Notebooks/Data Files categories.</double_penalty_prevention>
</areas_for_improvement>
</conditional_subsections>
</part_a_section>
<part_b_section>
<reflection_assessment>
<mandatory_check>
<condition>autograder_missing_reflections == true</condition>
<action>Manually scan .py files for genuine reflective content using different phrasing</action>
</mandatory_check>
<inclusion_rule>
<instruction>Include all found reflections in assessment</instruction>
<ta_requirement>Quote actual reflection text in TA-only section</ta_requirement>
</inclusion_rule>
<marking_adjustment>
<rule>Don't penalise for "missing" reflections if genuine reflective content exists</rule>
<evidence>Base Part B marks on actual reflective content found, not autograder detection</evidence>
</marking_adjustment>
<contextual_assessment>
<requirement>**MANDATORY**: Assess reflections in context of actual code evidence and course teaching progression. When forbidden libraries are used, be extra extremely sceptical of generic reflections that could apply to any data analysis task. **LOGICAL RULE**: If a student uses tools not yet taught in the course, their reflections about those tools CANNOT be genuine engagement with course material. Genuine reflection requires engagement with the actual course material being practised.</requirement>
</contextual_assessment>
<reflection_assessment_context>
<forbidden_libraries_used>
<student_facing_tone>sceptical</student_facing_tone>
<key_principle>Reflections about tools not yet taught cannot demonstrate engagement with course material</key_principle>
<mandatory_language>When you used [forbidden tools], your reflections about those tools cannot show engagement with the basic Python skills this assignment was designed to practise</mandatory_language>
<process_over_output>Focus on the learning process rather than technical correctness. The value lies in practising basic Python skills, not achieving correct results through advanced tools</process_over_output>
<prohibited_praise>Do NOT praise "thoughtful reflections" or "analytical thinking" when they concern forbidden tools</prohibited_praise>
</forbidden_libraries_used>
</reflection_assessment_context>
</reflection_assessment>
<general_requirements>
<feedback_style>Write concise feedback about reflection quality and analytical thinking</feedback_style>
<subheadings>Use two subheadings: "### Strengths" and "### Areas for Improvement" with concrete examples and short quotes</subheadings>
<formatting>Use H3 headings for substantial feedback, bullets for brief observations</formatting>
</general_requirements>
<conditional_assessment>
<pure_python_used>
<condition>code used pure Python correctly</condition>
<assessment>Assess reflections based on genuine engagement, depth, and personal voice using normal band categories (60-69% for good engagement with limited depth; 70-79% for good reflection with clear reasoning; etc.)</assessment>
</pure_python_used>
<forbidden_libraries_used>
<condition>forbidden libraries were used</condition>
<assessment>**Be highly sceptical**. Default to 50-59% unless reflections show convincing evidence of genuine engagement with basic Python. **LOGICAL RULE**: If a student uses tools not yet taught in the course, their reflections about those tools CANNOT be genuine engagement with course material. Genuine reflection requires engagement with the actual course material being practised. Add TA-only flag noting "possible AI-generated reflection".</assessment>
<sceptical_language>Your reflections focused on [forbidden tools] rather than the basic Python features we practised this week. This suggests you may not have engaged as deeply as you could with the course materials</sceptical_language>
<prohibited_praise>Do NOT praise "thoughtful reflections" or "analytical thinking" when they concern forbidden tools</prohibited_praise>
</forbidden_libraries_used>
</conditional_assessment>
<reflection_gradation_rules>
<zero_reflections>
<condition>No reflective content found in any section OR completely empty reflection sections</condition>
<marks>0-5 marks (0-19%)</marks>
<category>Unsatisfactory</category>
<student_feedback>We didn't find any reflections in your submission. This assignment asks for reflective thinking in sections 1, 3, and 4 of NB02 to help us understand your learning process. Adding reflections would help us see how you approached the challenges in this assignment.</student_feedback>
</zero_reflections>
<minimal_reflections>
<condition>Only 1-2 very brief, generic statements with no personal voice</condition>
<marks>6-11 marks (20-39%)</marks>
<category>Poor</category>
<student_feedback>Your reflections were quite brief. We found only [X] short statements that could have shown more of your thinking process or specific challenges you faced with this assignment.</student_feedback>
</minimal_reflections>
<generic_reflections>
<condition>Multiple reflections present but all generic, no personal voice, could apply to any assignment</condition>
<marks>12-14 marks (40-49%)</marks>
<category>Needs Work</category>
<student_feedback>Your reflections were present but quite general. They could have shown more of your personal experience or specific challenges you faced with this particular assignment.</student_feedback>
</generic_reflections>
<adequate_reflections>
<condition>Some personal engagement with valid explanations but limited depth</condition>
<marks>15-20 marks (50-69%)</marks>
<category>Satisfactory to Good</category>
<student_feedback>Your reflections showed some personal engagement and explained your thinking process, though they could have been more detailed about specific challenges.</student_feedback>
</adequate_reflections>
<strong_reflections>
<condition>Clear personal voice with specific challenges mentioned and clear reasoning</condition>
<marks>21+ marks (70%+)</marks>
<category>Very Good to Excellent</category>
<student_feedback>Your reflections demonstrated genuine engagement with the learning process, showing your thinking and specific challenges faced.</student_feedback>
</strong_reflections>
</reflection_gradation_rules>
</part_b_section>
<part_c_section>
<general_requirements>
<feedback_style>Write concise feedback about code quality and technical implementation</feedback_style>
<feedback_elements>
<what_where_how>state what, where (`NBXX` - Section X), and how to change it</what_where_how>
<before_after>include a tiny Before/After if helpful</before_after>
<plain_language>prefer plain words ("rare dates like 29 Feb") over jargon ("rare situations" not "edge cases")</plain_language>
<location_references>whenever referring to code, markdown content or reflections, always refer to them by the notebook and section name, like "`NB01`" or "`NB02` - Section X"</location_references>
<process_over_output>emphasise the learning process and skill development over output quality. This assignment focuses on practising basic Python skills, not just achieving correct results</process_over_output>
<requirements_understanding>look for evidence that students understood what data they actually needed for the problem. Collecting unnecessary variables suggests lack of problem understanding and copying API examples rather than thinking through requirements</requirements_understanding>
</feedback_elements>
<course_materials>Include at least one 🖥️ Lecture / 💻 Lab / 📝 Practice reference when issues are found</course_materials>
<concrete_feedback_requirement>**MANDATORY**: All feedback must be concrete and actionable. Never say "could be simplified" or "more straightforward approach" without explaining exactly what you mean and showing specific examples. Students need to understand WHY and HOW to improve. Always provide what, where, and how to change it.</concrete_feedback_requirement>
<ta_block>If forbidden libraries used, state which tools and confirm cap was applied. Otherwise, explain band justification normally</ta_block>
</general_requirements>
<conditional_subsections>
<forbidden_libraries_used>
<trigger>forbidden libraries were used</trigger>
<action>Start with a prominent "### Course Alignment Note" explaining the grave departure. Name the tools explicitly. Then add "### Other Feedback" for remaining points</action>
<mandatory_opening>Although your solution is technically correct, the process of your thinking has much more value to us in this course than the final outcome, which is why you scored lower here in Part C</mandatory_opening>
<prohibited_language>Do NOT praise technical correctness or problem-solving when forbidden libraries are used</prohibited_language>
<required_emphasis>Emphasise that using [forbidden tools] means you ignored the core learning process this assignment was designed to build</required_emphasis>
</forbidden_libraries_used>
<heatwave_detection_incorrect>
<trigger>heatwave detection and counting is not correct</trigger>
<action>Explain where the logic error lies (explain like a pseudocode but also shows before/after code blocks). Deduct marks. If significant, cap at "Satisfactory"</action>
</heatwave_detection_incorrect>
<pure_python_used>
<trigger>pure Python was used correctly</trigger>
<action>Use "### Strengths" and "### Areas for Improvement" subheadings. NO "Course Alignment Note" section</action>
</pure_python_used>
</conditional_subsections>
</part_c_section>
</content_guidelines>
## Marks Calculation
**ALWAYS run the calculation script before finalizing feedback:**
```bash
calculate_marks <repo_structure (int)> <notebooks (int)> <data_files (int)> <readme (int)> <pure_python (int)> <part_b (int)> <part_c (int)>
```
**Part A Marking from Autograder Data:**
<part_a_marking_logic>
<repository_structure>
<marks>8</marks>
<grading>
<perfect>8/8: Perfect structure with all files in correct locations and names</perfect>
<minor_issues>6/8: Minor naming issues (e.g., wrong CSV filename) but files exist in correct locations</minor_issues>
<location_issues>4/8: Files exist but in wrong locations (e.g., notebooks in data/ folder)</location_issues>
<partial_structure>2-3/8: Some files exist but major structural issues (e.g., only NB01 present, data in wrong folder)</partial_structure>
<missing_files>0/8: Missing required files entirely</missing_files>
</grading>
</repository_structure>
<notebooks>
<marks>10</marks>
<grading>
<both_present>10/10: Both NB01 and NB02 exist and functional (regardless of location)</both_present>
<one_present>5/10: Only one notebook present and functional</one_present>
<none_present>0/10: No functional notebooks</none_present>
</grading>
</notebooks>
<data_files>
<marks>10</marks>
<grading>
<json_component>5 marks for JSON file</json_component>
<json_perfect>5/5: Exists with correct name and format in correct location</json_perfect>
<json_minor>4/5: Exists with correct format but minor naming issue OR wrong location</json_minor>
<json_wrong_location>3/5: Exists with correct format but in wrong location (e.g., in root instead of data/)</json_wrong_location>
<json_missing>0/5: Missing entirely</json_missing>
<csv_component>5 marks for CSV file</csv_component>
<csv_perfect>5/5: Exists with correct name, format, and data structure in correct location</csv_perfect>
<csv_minor>3-4/5: Exists with correct format and data but wrong filename</csv_minor>
<csv_wrong_location>3/5: Exists with correct format and data but in wrong location (e.g., in root instead of data/)</csv_wrong_location>
<csv_format_issues>2-3/5: Exists but has format issues (wrong headers, missing years, etc.) regardless of location</csv_format_issues>
<csv_missing>0/5: Missing entirely</csv_missing>
</grading>
</data_files>
<readme>
<marks>7</marks>
<condition>if present (TA evaluates content)</condition>
<penalty>0 if missing</penalty>
</readme>
<pure_python>
<marks>5</marks>
<condition>if allowlist_only=true AND top_grouped=true</condition>
<penalty>deduct for scattered imports or forbidden features</penalty>
</pure_python>
</part_a_marking_logic>
**IMPORTANT**: Use proportional marking for Part A. Be generous with partial credit - minor issues should receive partial credit, not zero marks. Remember that this is a formative assignment designed to help students learn.
**Proportional Marking Guidelines:**
- **Repository Structure**: Use graduated marking (8/8, 6/8, 4/8, 2-3/8, 0/8) based on severity of issues
- **Notebooks**: Give partial credit for partial completion (10/10 for both, 5/10 for one, 0/10 for none)
- **Data Files**: Separate JSON (5 marks) and CSV (5 marks) components with generous partial credit
- **Generous Examples**:
- Wrong CSV filename but correct content → CSV: 3-4/5, Repository Structure: 6/8
- Files in wrong locations but present → Repository Structure: 4/8, Data Files: 3/5+3/5=6/10 (not 0/10)
- JSON in wrong folder but present → JSON: 3/5, Repository Structure: 4/8
- Only NB01 present + JSON in wrong location → Notebooks: 5/10, JSON: 3/5, Repository Structure: 2-3/8
- Only NB01 present + no CSV → Notebooks: 5/10, JSON: 3/5, CSV: 0/5, Repository Structure: 2-3/8
- Format issues (wrong headers) → CSV: 2-3/5, not 0/5
- **Be generous with partial credit** - only give 0 marks for completely missing files or non-functional code
**Double-Penalty Prevention:**
- If `structure_ok=false` due to location issues, do NOT also penalize Notebooks/Data Files for location
- If `structure_ok=false` due to missing files, then Notebooks/Data Files can also be 0
- Example: Wrong CSV filename → Repository Structure: 6/8, Data Files: 8/10 (5+3), not 0/10
- Example: Both files in wrong location → Repository Structure: 4/8, Data Files: 6/10 (3+3), not 0/10
- Example: Missing CSV entirely → Repository Structure: 0/8, Data Files: 5/10 (5+0)
**Band Expectations:**
<band_expectations>
<part_a_objective>
<description>Can score 90-100% easily as it's based on objective criteria</description>
</part_a_objective>
<parts_b_c_subjective>
<description>High bands require both correct outcomes AND alignment with the week's basics</description>
</parts_b_c_subjective>
<critical_rule>
<description>Do NOT award 70%+ in Parts B or C if the submission bypassed the practised skills with non-basic libraries</description>
</critical_rule>
<grave_departure>
<description>Apply caps regardless of output quality (Part C: 40-49%, Part B: default 50-59%)</description>
</grave_departure>
<band_60_69>
<description>For students who followed course approach with some mistakes</description>
</band_60_69>
<band_70_79>
<description>Only if we couldn't fault them on anything significant AND they used course basics</description>
</band_70_79>
<band_80_plus>
<description>Only if they surprised us with exceptional work WITHIN the course constraints</description>
</band_80_plus>
</band_expectations>
## Band-to-Marks Mapping
<band-categories part="A" total-marks="40">
<band percentage="90-100" marks="36-40" category="Excellent">
All requirements met nearly perfectly
</band>
<band percentage="80-89" marks="32-35" category="Very Good!">
Minor issues only
</band>
<band percentage="70-79" marks="28-31" category="Good">
Some important misses but mostly correct
</band>
<band percentage="60-69" marks="24-27" category="Satisfactory">
Several issues but core requirements met
</band>
<band percentage="50-59" marks="20-23" category="Needs Work">
Major issues but some requirements met
</band>
<band percentage="40-49" marks="16-19" category="Poor">
Significant issues
</band>
<band percentage="<40" marks="0-15" category="Unsatisfactory">
Major failures
</band>
</band-categories>
<band-categories part="B" total-marks="30">
<band percentage="90-100" marks="27-30" category="WOW!">
Exceptionally authentic reflection with sophisticated understanding
</band>
<band percentage="80-89" marks="24-26" category="Excellent!">
Genuine personal voice with clear reasoning and trade-off awareness
</band>
<band percentage="70-79" marks="21-23" category="Very Good!">
Good reflection with specific challenges mentioned and clear reasoning
</band>
<band percentage="60-69" marks="18-20" category="Good">
Some personal engagement with valid explanations but limited depth
</band>
<band percentage="50-59" marks="15-17" category="Satisfactory">
Mostly generic reflections, limited personal engagement, or lacks depth
</band>
<band percentage="40-49" marks="12-14" category="Needs Work">
Generic responses with little personal engagement
</band>
<band percentage="20-39" marks="6-11" category="Poor">
Minimal reflections with no personal voice or very generic responses
</band>
<band percentage="0-19" marks="0-5" category="Unsatisfactory">
**ZERO REFLECTIONS**: No reflective content found in any section OR completely empty reflection sections
</band>
<special-rule name="when_non_alignment_rule_applies">
See <non_alignment_rule> above. If triggered (forbidden libraries used), default Part B to 50-59% (15-17 marks) unless reflections show convincing evidence of genuine engagement with basic Python. [Generic reflections about data structures while using advanced libraries do NOT count as evidence of basic Python engagement. Reflections must align with course teaching progression - reflecting on tools not yet taught shows lack of course awareness.] Be highly sceptical. Add TA flag for possible AI-generated content.
</special-rule>
</band-categories>
<band-categories part="C" total-marks="30">
<band percentage="90-100" marks="27-30" category="WOW!">
WOW factor - creative and excellent implementation with good alignment with what was taught in the course
</band>
<band percentage="80-89" marks="24-26" category="Excellent!">
Excellent attention to detail, deep understanding of principles as taught in the course
</band>
<band percentage="70-79" marks="21-23" category="Very Good!">
Well-organised code with good logical flow, evidence of course engagement
</band>
<band percentage="60-69" marks="18-20" category="Good">
Generally good implementation with some issues
</band>
<band percentage="50-59" marks="15-17" category="Satisfactory">
Basic implementation working but with notable issues
</band>
<band percentage="40-49" marks="12-14" category="Needs Work">
Poor organisation, unclear logic, or signs of uncritical copy-paste
</band>
<band percentage="<40" marks="0-11" category="Poor">
Major failures in code quality and organisation
</band>
<special-rule name="when_non_alignment_rule_applies">
See <non_alignment_rule> above. If triggered (forbidden libraries used for core tasks), Part C is automatically capped at 40-49% (12-14 marks) regardless of output quality. Include prominent "Course Alignment Note" in student-facing feedback and "Band cap justification" in TA block.
</special-rule>
</band-categories>
## Output Requirements
### Template Structure
**⚠️ CRITICAL: The template uses XML-like tags for processing instructions - these are NOT to be included in the final output!**
The template uses XML-like tags for processing instructions - these are NOT to be included in the final output:
- **`{PLACEHOLDER}`**: Replace with actual content (e.g., `{USERNAME}` → `github-username`)
- **`<if condition="...">`**: Include this section only if condition is true - REMOVE the entire tag
- **`<student_facing>`**: Content visible to students - REMOVE the tag, keep only the content.
- **`<ta_only>`**: Content in grey box for TA/Jon eyes only - REMOVE the tag, keep only the content. Information about autograders or other technical details should only be included in the `<ta_only>` block - not student-facing text.
- **`content_type="..."`**: Processing hint - REMOVE this attribute entirely
### Writing Process
1. **Replace all `{PLACEHOLDERS}`** with actual content based on student work
2. **Evaluate `<if condition="...">` tags** and include/exclude sections accordingly:
- `structure_ok == false` → Include "File Structure Issues" subsection
- `non_alignment_rule_triggered == true` → Include "Course Alignment Note" in Part C
- `feedback_needs_subsections == true` → Use H3 headings; otherwise use bullets
- `before_after_helpful == true` → Include code comparison example
3. **Remove ALL XML tags** from final output - these are processing instructions only:
- Remove `<if condition="...">` and `</if>` tags completely
- Remove `<student_facing>` and `</student_facing>` tags, keep content
- Remove `<ta_only>` and `</ta_only>` tags, keep content in grey boxes
- Remove `content_type="..."` attributes entirely
4. **Apply formatting** as indicated by `content_type` attributes (then remove them)
5. **Use British spelling consistently** in all student-facing text
6. **Use exact marks** from calculation script output
**Example of correct processing:**
- Template: `<student_facing content_type="paragraph">Your code works well.</student_facing>`
- Final output: `Your code works well.`
- Template: `<if condition="structure_ok == false">### File Structure Issues</if>`
- Final output: (only include if condition is true, remove the tags)
### Final Checklist
- [ ] All `{PLACEHOLDERS}` replaced with actual content
- [ ] All `<if>` conditions evaluated correctly
- [ ] **ALL XML tags completely removed from output** (no `<if>`, `<student_facing>`, `<ta_only>`, or `content_type` attributes)
- [ ] **MANDATORY Manual reflection check completed**: Scanned .py files for additional reflective content beyond autograder detection (no grepping)
- [ ] **All genuine reflections included**: Part B assessment reflects actual reflective content found, not just autograder detection
- [ ] **Manual reflection quotes included**: TA-only section quotes actual reflection text from manual findings
- [ ] **ZERO REFLECTIONS CHECK**: If no reflections found, award 0-5 marks (0-19%) and use "Unsatisfactory" category
- [ ] **REFLECTION GRADATION APPLIED**: Use specific gradation rules based on quantity and quality of reflections found
- [ ] **SCEPTICISM ALIGNMENT CHECK**: If forbidden libraries used, ensure sceptical tone throughout all parts (not just Part C)
- [ ] **DOUBLE-PRAISE PREVENTION**: No "thoughtful reflections" + "forbidden libraries" inconsistency
- [ ] **PROCESS-OVER-OUTPUT CONSISTENCY**: When forbidden libraries used, all parts emphasize learning process over technical output
- [ ] TA-only blocks properly formatted with grey divs
- [ ] Inline code formatting applied (`` `NB01` ``, `` `pandas` ``, etc.)
- [ ] Location references use "`NB0X` - Section Y" format (no line numbers in student text)
- [ ] Queue file updated with `- ☑️ DONE`
- [ ] Band caps applied if non-alignment rule triggered
## Error Handling
- If `autograder_facts.json` or `autograder_brief.md` missing → add `🚫 MISSING AUTOGRADER INFO` and continue
- If processing errors occur → log them and continue to next student
- Always update queue file to reflect current processing state
## Evidence Markers & Course Material References (MANDATORY)
**ALWAYS consult the evidence markers below before writing feedback:**
<evidence_markers>
<marker id="W04-JSON-WRITE" taxonomy="DS105A-JSON-002" name="JSON file writing" part="A" visible_where="NB01">
<description>Student writes collected API data to JSON</description>
<detection>Autograder checks existence of data/london_temperatures_1990_2025.json</detection>
<feedback_pointer>Refer to the notebooks/slides shared in 🖥️ **W03 Lecture** and 💻 **W03 Lab** to find the relevant `json.dump()` code with the `with open()` pattern</feedback_pointer>
</marker>
<marker id="W04-JSON-READ" taxonomy="DS105A-JSON-003" name="JSON file reading" part="A" visible_where="NB02">
<description>Student reads JSON into Python structures</description>
<detection>Autograder inspects imports and cell content</detection>
<feedback_pointer>Refer to the notebooks/slides shared in 🖥️ **W03 Lecture** and 💻 **W03 Lab** to find the relevant `json.load()` code with the `with open()` pattern</feedback_pointer>
</marker>
<marker id="W04-CSV-WRITE" taxonomy="DS105A-CSV-001" name="CSV file writing" part="A" visible_where="CSV">
<description>Student writes per-year heatwave counts to CSV</description>
<detection>Header + structure checks</detection>
<feedback_pointer>Refer to the notebooks/slides shared in 🖥️ **W03 Lecture** and 💻 **W03 Lab** to find the relevant `csv.writer()` code with the `with open()` pattern</feedback_pointer>
</marker>
<marker id="W04-FOR-LOOP" taxonomy="DS105A-PYTHON-003" name="For loop implementation" part="B" visible_where="NB02">
<description>Student implements for loops appropriately</description>
<detection>AI detects/quotes evidence from .py export</detection>
<feedback_pointer>Refer to 📝 **W03 Practice** Task 4 (DataQuest Python for loops lesson) and 💻 **W03 Lab** Part III for loop patterns to process temperature data</feedback_pointer>
</marker>
<marker id="W04-CONDITIONAL" taxonomy="DS105A-PYTHON-004" name="Conditional statements" part="B" visible_where="NB02">
<description>Student uses conditionals for logic</description>
<detection>AI detects/quotes evidence from .py export</detection>
<feedback_pointer>Refer to 📝 **W03 Practice** Task 4 (DataQuest If/Else/Elif lessons) and 💻 **W03 Lab** Part III for conditional logic examples</feedback_pointer>
</marker>
<marker id="W04-GIT-BASIC" taxonomy="DS105A-GIT-001" name="Basic Git operations" part="A" visible_where="commits">
<description>Student uses Git workflow appropriately</description>
<detection>Autograder parses commit list</detection>
<feedback_pointer>Refer to 🖥️ **W03 Lecture** Section 6 (Git ceremony pattern: git status → git add . → git commit → git push) and 💻 **W03 Lab** post-lab GitHub setup</feedback_pointer>
</marker>
<marker id="W04-GIT-MESSAGES" taxonomy="DS105A-GIT-002" name="Meaningful commit messages" part="B" visible_where="commits">
<description>Commit templates matched and/or descriptive messages</description>
<detection>Autograder tallies matches; AI notes quality</detection>
<feedback_pointer>Refer to 🖥️ **W03 Lecture** Git section for meaningful commit message examples and 📝 **W04 Practice** suggested commit messages</feedback_pointer>
</marker>
<marker id="W04-WORKFLOW-PIPELINE" taxonomy="DS105A-WORKFLOW-001" name="Pipeline recognition" part="B" visible_where="NB01|NB02|README">
<description>Understands collect→store→analyse→document</description>
<detection>AI infers from notebook sectioning and README</detection>
<feedback_pointer>Refer to 🖥️ **W01 Lecture** (data science workflow framework: COLLECT→STORE→PREPARE→EXPLORE→COMMUNICATE) and 💻 **W01 Lab** Q8 (workflow positioning exercise)</feedback_pointer>
</marker>
<marker id="W04-WORKFLOW-POSITION" taxonomy="DS105A-WORKFLOW-002" name="Stage positioning" part="A" visible_where="NB01|NB02">
<description>Keeps collection (NB01) separate from analysis (NB02)</description>
<detection>Autograder verifies NB02 headings presence</detection>
<feedback_pointer>Refer to 📝 **W04 Practice** instructions (NB01 for collection, NB02 for analysis separation) and 🖥️ **W01 Lecture** workflow stages</feedback_pointer>
</marker>
<marker id="W04-COMM-REFLECTION" taxonomy="DS105A-COMM-002" name="Analytical reflection" part="B" visible_where="NB02">
<description>Analytical reflection on decisions and trade-offs</description>
<detection>AI quotes indicators; TA judges authenticity</detection>
<feedback_pointer>Reflections are quite important in this course! It makes your thinking, in your own words, visible to us. Seeing your process is more valuable to us than a polished final outcome.
👉 Refer to 📝 **W01 Practice** (analytical reflection examples) to remember how you were asked to write reflections in the past. You can also review the precise requirements in 📝 **W04 Practice** for where we expected you to write reflections in this assignment.</feedback_pointer>
</marker>
<marker id="W04-AI-DOC" taxonomy="NA" name="AI usage documentation" part="A" visible_where="NB02">
<description>AI usage documented with link</description>
<detection>Not a skill; still tracked</detection>
<feedback_pointer>It would have been great if you had told us how you used AI to help you with the assignment.</feedback_pointer>
</marker>
<marker id="W04-CSV-NONZERO-ONLY" taxonomy="DS105A-CSV-001" name="CSV completeness" part="A" visible_where="CSV">
<description>CSV includes zero-count years</description>
<detection>Autograder flags non_zero_only or sorted/duplicates</detection>
<feedback_pointer>Even though this is technically correct, we would like to have seen all years (even those with zero heatwave counts) in the CSV. This would match the research question posed in the 📝 **W04 Practice** requirement more closely.</feedback_pointer>
</marker>
<marker id="W04-HEADINGS-NB02" taxonomy="NA" name="NB02 required sections" part="A" visible_where="NB02">
<description>All 5 NB02 sections present</description>
<detection>Structural requirement, not a skill</detection>
<feedback_pointer>Refer to the 📝 **W04 Practice** instructions (NB02 must have the following H2 headings demarcating the sections: Sections 1-5: Data Loading, Identifying Hot Days, Subset of Hot Days, Recreating the CSV, AI Usage Documentation)</feedback_pointer>
<additional_checks>If student has "sections" but they are regular text instead of the expected H2 headings, the feedback must explain how Markdown headings work and how to use them correctly in code blocks.</additional_checks>
</marker>
<marker id="W04-CONSTRAINTS-PY" taxonomy="NA" name="Constraint compliance" part="A" visible_where="NB01|NB02">
<description>Allowlist-only imports; no forbidden features</description>
<detection>Imports grouped; allowlist-only; no forbidden features</detection>
<feedback_pointer>In the 📝 **W04 Practice** assignment, we explicitly state that you are only allowed to use pure Python and to the level we have covered in the course so far. Please revisit the Dataquest lessons (and your notes on it)that you went through in the 📝 **W02 Practice** and 📝 **W03 Practice**. Refer, also, to code shared during the 🖥️ **W02 Lecture** and 💻 **W03 Lab**. Using `pandas` or `datetime` or more specialised Python at this stage suggests you are not fully aligned with the teaching we are doing in this course. </feedback_pointer>
</marker>
</evidence_markers>
**When writing feedback that requires course material references:**
1. **Check evidence markers above** for the specific marker that appears in `autograder_facts.json`
2. **Use the feedback_pointer** to direct students to specific course materials where concepts were taught
3. **Read W04 specifics** within `DS105/src/2025-2026/autumn-term/pedagogical-mapping/` (specifically `2025-2026-ds105a-w04-specifics.md`) to understand what is expected of the student in the assignment.
4. **Use exact file names and titles** from both sources
5. **Include at least one material reference** when structure or basics are violated
6. **Format all code, package names, and notebook references** with inline backticksWhat the AI draft template looks like
# W04 Practice - AI Draft Marking Report
Student: {{FULL_NAME}} • GitHub Username: {{GITHUB_USERNAME}} • Candidate Number: {{CANDIDATE_NUMBER or '**NOT PROVIDED!**'}}
---
## Summary
<student_facing content_type="paragraph">
{{CONCISE_SUMMARY_ACROSS_ALL_PARTS}}
</student_facing>
**Marks Breakdown**
| Category | Mark | Band | Key Reason |
|-----------------------------|--------|---------------|------------------------------|
| Objective Checks (Part A) | {{A_MARKS}}/40 | {{BAND_A_NAME}}<br/>{{PERCENTAGE_A}} | {{KEY_REASON_A}} |
| Documentation & Reflection (Part B) | {{B_MARKS}}/30 | {{BAND_B_NAME}}<br/>{{PERCENTAGE_B}} | {{KEY_REASON_B}} |
| Technical Excellence (Part C)| {{C_MARKS}}/30 | {{BAND_C_NAME}}<br/>{{PERCENTAGE_C}} | {{KEY_REASON_C}} |
| **Total** | **{{TOTAL_MARKS}}/100** | | |
<ta_only>
<div style="background-color: #f5f5f5; padding: 15px; border-left: 4px solid #666; margin: 20px 0; font-size: 0.9em; color: #666;">
**<NOT STUDENT-FACING | TAs EYES ONLY>**
**⚠️ Marks and bands verified with a Python script so all calculations _should_ be correct. But you should always double-check!**
</div>
</ta_only>
## Part A - Objective Checks
<student_facing content_type="one_line_summary">
{{ONE_LINE_SUMMARY_PART_A}}
</student_facing>
**Band: {{BAND_A_NAME}} ({{PERCENTAGE_A}})**
**Marks: {{A_MARKS}}/40**
<student_facing content_type="requirement_checklist">
- **Repository Structure**: {{REPO_STRUCTURE_MARKS}}/8 marks ({{ICON_PASS_OR_FAIL}}) - {{BRIEF_EXPLANATION}}
- **Notebooks Present & Functional**: {{NOTEBOOKS_MARKS}}/10 marks ({{ICON_PASS_OR_FAIL}}) - {{BRIEF_EXPLANATION}}
- **Data Files Created**: {{DATA_FILES_MARKS}}/10 marks ({{ICON_PASS_OR_FAIL}}) - {{BRIEF_EXPLANATION}}
- **README Documentation**: {{README_MARKS}}/7 marks ({{ICON_PASS_OR_FAIL}}) - {{BRIEF_EXPLANATION}}
- **Pure Python Usage**: {{PURE_PYTHON_MARKS}}/5 marks ({{ICON_PASS_OR_FAIL}}) - {{BRIEF_EXPLANATION}}
</student_facing>
<if condition="structure_ok == false">
### File Structure Issues
<student_facing content_type="file_tree">
{{FILE_TREE_SHOWING_ERRORS}}
</student_facing>
<student_facing content_type="course_references">
{{COURSE_MATERIAL_REFERENCES}}
</student_facing>
</if>
<if condition="has_areas_for_improvement == true">
### Areas for Improvement
<student_facing content_type="plain_text_with_code_formatting">
{{AREA_1_WHAT_WHERE_HOW}}
{{AREA_2_WHAT_WHERE_HOW}}
{{AREA_N_WHAT_WHERE_HOW}}
</student_facing>
</if>
<ta_only>
<div style="background-color: #f5f5f5; padding: 15px; border-left: 4px solid #666; margin: 20px 0; font-size: 0.9em; color: #666;">
**<NOT STUDENT-FACING | TAs EYES ONLY>**
**Band suggestion:** {{BAND_PERCENTAGE_RANGE}} based on the following evidence:
- {{EVIDENCE_ITEM_1}}
- {{EVIDENCE_ITEM_2}}
- {{EVIDENCE_ITEM_N}}
```markdown
{{FULL_AUTOGRADER_BRIEF_MD_CONTENT}}
```
</div>
</ta_only>
## Part B - Documentation & Reflection
<student_facing content_type="paragraph">
{{OVERALL_REFLECTION_FEEDBACK}}
</student_facing>
<if condition="feedback_simple == true">
<student_facing content_type="bullet_list">
- {{STRENGTH_OR_AREA_1}}
- {{STRENGTH_OR_AREA_2}}
- {{STRENGTH_OR_AREA_N}}
</student_facing>
</if>
<if condition="feedback_needs_subsections == true">
### Strengths
<student_facing content_type="bullet_list_with_quotes">
- {{STRENGTH_WITH_QUOTE}}
- {{STRENGTH_WITH_QUOTE}}
</student_facing>
### Areas for Improvement
<student_facing content_type="plain_text_with_specifics">
{{AREA_WHAT_WHERE_HOW}}
{{AREA_WHAT_WHERE_HOW}}
</student_facing>
</if>
**Band: {{BAND_B_NAME}} ({{PERCENTAGE_B}})**
**Marks: {{B_MARKS}}/30**
<ta_only>
<div style="background-color: #f5f5f5; padding: 15px; border-left: 4px solid #666; margin: 20px 0; font-size: 0.9em; color: #666;">
**<NOT STUDENT-FACING | TAs EYES ONLY>**
**Band suggestion:** {{BAND_PERCENTAGE_RANGE}}
<if condition="non_alignment_rule_triggered == true">
**Scepticism check:** Code uses non-basic libraries ({{LIST_FORBIDDEN_TOOLS}}). Defaulting to 50-59% unless reflections show specific, course-grounded engagement with basic tools. [Generic reflections about data structures while using advanced libraries do NOT count as evidence of basic Python engagement. Reflections must align with course teaching progression - reflecting on tools not yet taught shows lack of course awareness.] Flagging possible AI-generated content.
</if>
### Reflections Found
- {{NB_LOCATION_1}} (found by autograder): "{{REFLECTION_QUOTE_1}}"
- {{NB_LOCATION_2}} (found by LLM later): "{{REFLECTION_QUOTE_2}}"
- {{NB_LOCATION_N}} (found by {{FOUND_BY_SOURCE_N}}): "{{REFLECTION_QUOTE_N}}"
Detection summary (not student-facing):
- Total reflections: {{TOTAL_REFLECTION_COUNT}}
- Found by autograder: {{AUTOGRADER_COUNT}}
- Found by LLM later: {{LLM_COUNT}}
Locations:
- {{NB_LOCATION_1}} (autograder)
- {{NB_LOCATION_2}} (LLM later)
- {{NB_LOCATION_N}} ({{FOUND_BY_SOURCE_N}})
{{BAND_JUSTIFICATION_TEXT}}
</div>
</ta_only>
## Part C - Technical Excellence
<student_facing content_type="paragraph">
{{OVERALL_TECHNICAL_FEEDBACK}}
</student_facing>
<if condition="non_alignment_rule_triggered == true">
### Course Alignment Note
<student_facing content_type="direct_plain_language">
You used {{FORBIDDEN_TOOLS_LIST}} where you were supposed to use only the basic Python features we practised this week (lists, dictionaries, loops, conditionals).
</student_facing>
<student_facing content_type="code_comparison">
**Here is a snippet of your code that is not aligned with the course materials:**
```python
{{EXAMPLE_OF_THEIR_NON_ALIGNED_CODE}}
```
**A solution aligned with the course materials would be:**
```python
{{EXAMPLE_OF_ALIGNED_CODE}}
```
</student_facing>
<student_facing content_type="course_references">
{{COURSE_MATERIAL_REFERENCES}}
</student_facing>
<student_facing content_type="warning_box">
📝 **W04 Practice** focuses on building confidence with Python fundamentals. Using {{FORBIDDEN_TOOLS_LIST}} bypasses the learning process and suggests you may not be engaging as much as you could with the teaching materials we have in lectures and labs. This is reflected in your Part C marks.
</student_facing>
### Other Feedback
<student_facing content_type="condensed_feedback">
{{REMAINING_TECHNICAL_FEEDBACK_IF_ANY}}
</student_facing>
</if>
<if condition="non_alignment_rule_triggered == false">
<if condition="feedback_simple == true">
<student_facing content_type="bullet_list">
- {{STRENGTH_OR_AREA_1}}
- {{STRENGTH_OR_AREA_2}}
- {{STRENGTH_OR_AREA_N}}
</student_facing>
</if>
<elseif condition="feedback_needs_subsections == true">
### Strengths
<student_facing content_type="bullet_list">
- {{STRENGTH_1}}
- {{STRENGTH_2}}
- {{STRENGTH_N}}
</student_facing>
### Areas for Improvement
<student_facing content_type="what_where_how_with_examples">
{{ISSUE_DESCRIPTION_NBXX_SECTION_Y}}
<if condition="before_after_helpful == true">
**Before:**
```python
{{THEIR_CODE_WITH_ISSUE}}
```
**After:**
```python
{{IMPROVED_CODE_EXAMPLE}}
```
</if>
{{COURSE_MATERIAL_REFERENCE}}
</student_facing>
</elseif>
</if>
**Band: {{BAND_C_NAME}} ({{PERCENTAGE_C}})**
**Marks: {{C_MARKS}}/30**
<ta_only>
<div style="background-color: #f5f5f5; padding: 15px; border-left: 4px solid #666; margin: 20px 0; font-size: 0.9em; color: #666;">
**<NOT STUDENT-FACING | TAs EYES ONLY>**
**Band suggestion:** {{BAND_PERCENTAGE_RANGE}}
<if condition="non_alignment_rule_triggered == true">
**Band cap justification:** Student used {{LIST_EXACT_TOOLS_FOUND}} for core tasks. Part C capped at 40-49% (12-14 marks) per non-alignment rule regardless of output quality.
</if>
The suggested band is based on the evidence given by the relevant code snippets or markdown content snippets which are copy-pasted below:
- **{{LOCATION_DESCRIPTION_WITH_LINES}}**:
```python
{{CODE_SNIPPET}}
```
- **{{LOCATION_DESCRIPTION_WITH_LINES}}**:
```python
{{CODE_SNIPPET}}
```
- **{{LOCATION_DESCRIPTION}}**:
> _{{MARKDOWN_CONTENT_SNIPPET}}_
{{BAND_JUSTIFICATION_TEXT}}
</div>
</ta_only>
---
## Skills Evidence (by taxonomy)
<ta_only content_for="Jon">
<div style="background-color: #f5f5f5; padding: 15px; border-left: 4px solid #666; margin: 20px 0; font-size: 0.9em; color: #666;">
**<JON'S EYES ONLY>**
{{SPECIFIC_EVIDENCE_FOR_EACH_SKILL_FROM_TAXONOMY}}
{{LIST_UNMATCHED_EVIDENCE_IF_ANY}}
</div>
</ta_only>What the marker sees

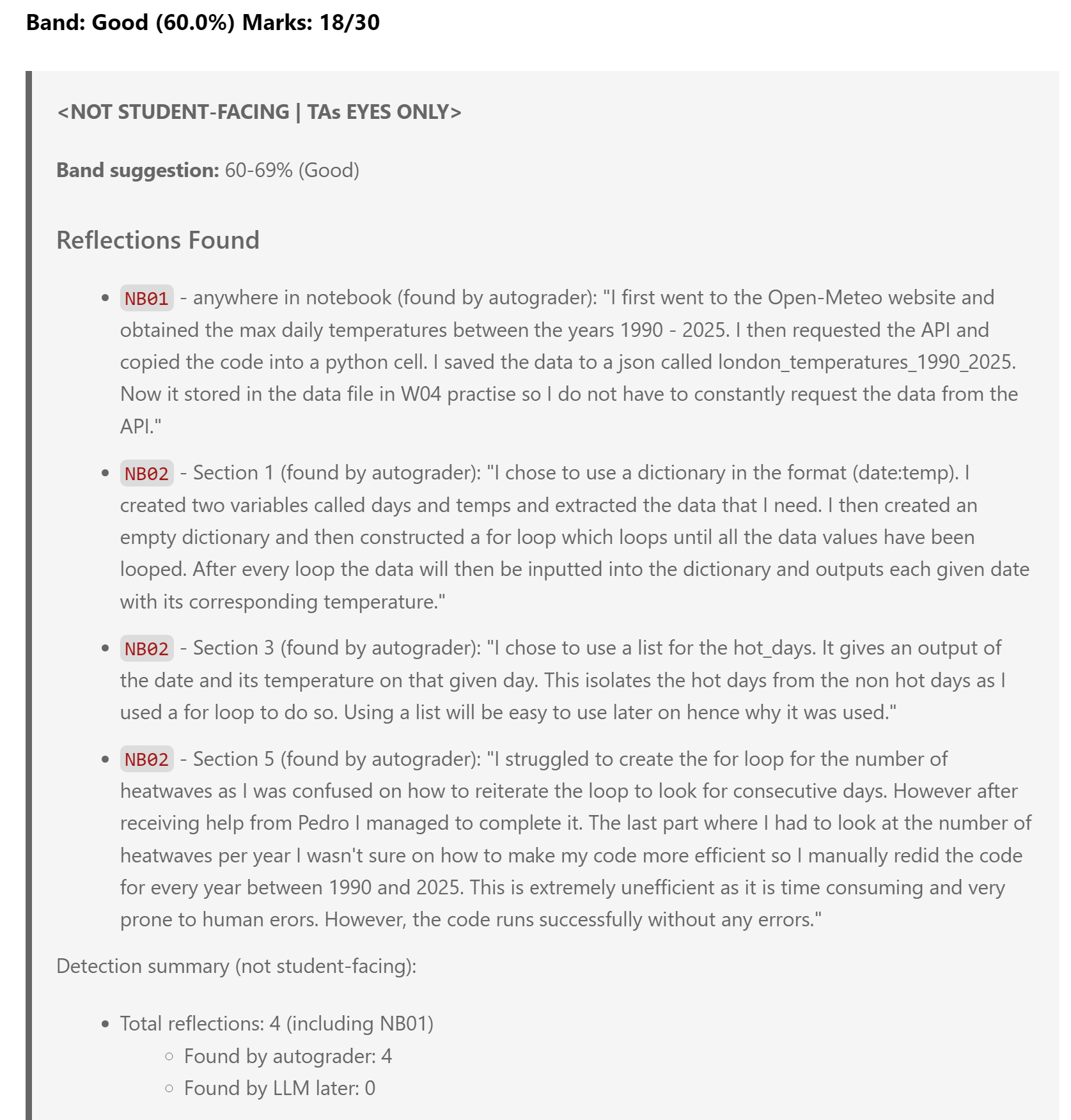
How we’re finding it:
AI-Human Alignment
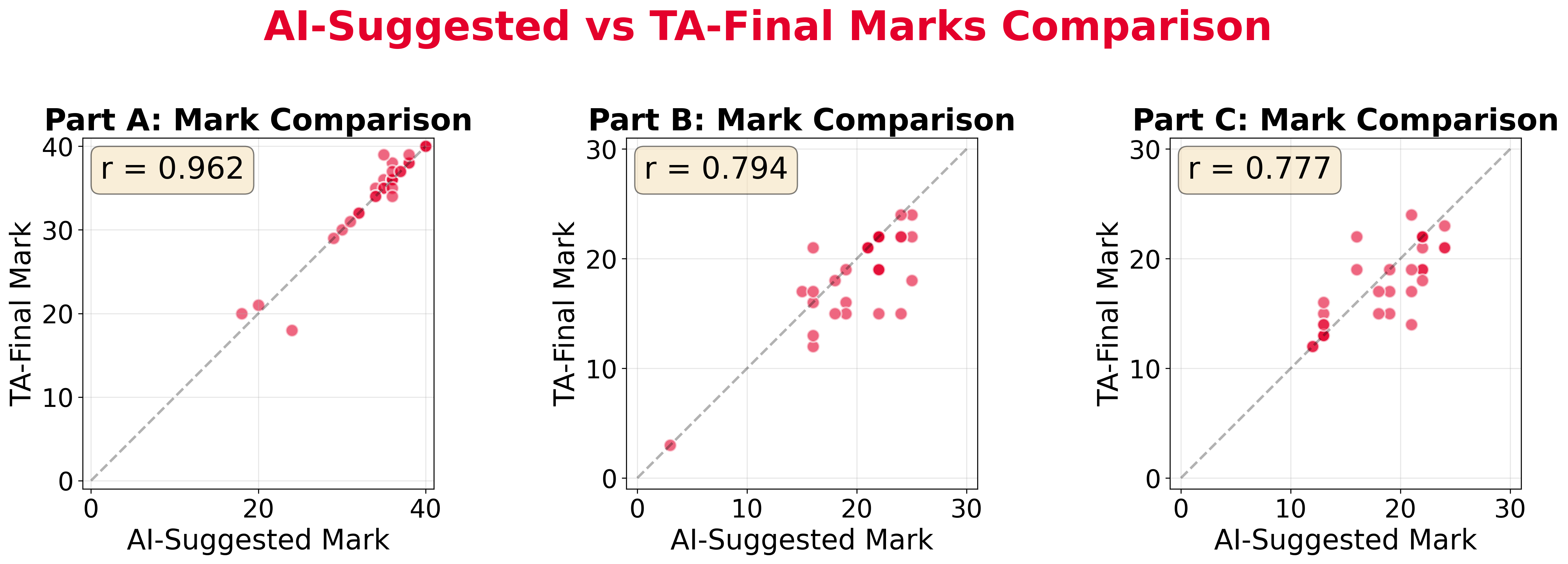
- AI can be trusted with Part A (the most objective)
- Not so much with the more qualitative aspects (Part B and Part C)
What my GTAs are saying
The draft was a very useful pointer for marking. It was particularly helpful for things like checking commit history, and picked up on small details that I may have missed, like the formatting of sections and file names - it picked up that there was an error because of extra spaces in the file name. I was actually very impressed by the ability to pick up on every small detail. It’s also really helpful for setting guidelines with marks and bands.
I don’t think it distracted me, I was making mental notes about what feedback I’d write, then cross-checking with the points in the draft. For most of the assignments, the majority of the points that I would have written were picked up by the draft, and fleshed out into complete points.
Overall, I think for the next lot of marking it would save me time, with this formative it probably took longer as I spent the first 10 assignments double checking everything that was produced down to the smallest detail (trust issues). Overall it was a net positive, there were definitely benefits to having this draft, though the marking sheet could be tweaked to streamline everything.
Thank You!
We have a preprint out 🎉
Cardoso-Silva, J., Sallai, D., Kearney, C., Panero, F., & Barreto, M. E. (2025). Mapping Student-GenAI Interactions onto Experiential Learning: The GENIAL Framework. SSRN Electronic Journal. Available at https://papers.ssrn.com/sol3/papers.cfm?abstract_id=5674422


E-mail: 📧 J.Cardoso-Silva@lse.ac.uk

Cardoso-Silva (2025). Agent AI Strategy for Marking. Cambridge GenAI in Education Conference 2025 | Session 7B