Forming Computational Social Scientists in the Era of Generative AI

19 May 2026
The ![]() GENIAL study
GENIAL study
(Part 1/4)
When do Generative AI tools act as a catalyst for learning?
Who I am and what I teach


- I am a Assistant Professor (Education) based at the Data Science Institute * at the London School of Economics and Political Science(LSE).
- I teach data science courses that involve programming, web scraping, data engineering, version control.
- My pedagogical approach is for project-based learning, continuous feedback cycles, and authentic assignments - everything is assessed through coursework, with no exams.
LSE AI and Education Fellow (2025–2027)
I am one of the 10 LSE Fellows in AI and Education, a programme with an ambitious goal to test out how to embed Generative AI in the teaching & learning practices of our disciplines.
* (I’m moving to the LSE Department of Methodology as an Associate Professor in September)
Data from our study (2023-2025)
Although the opinions are mine, some of the data and preliminary findings come from the  GENIAL study.
GENIAL study.
- A collaborative project across several LSE departments
- Data Science Institute
- Department of Statistics
- Department of Management
- School of Public Policy
- Timeline: July 2023 to April 2024
- Funding: internal (LSE Eden Centre for Educational Enhancement, LSE Data Science Institute)
We asked students to share their chat logs and in the case of my data science courses, I also collected the git histories of their assignments.

Attitudes: Tools
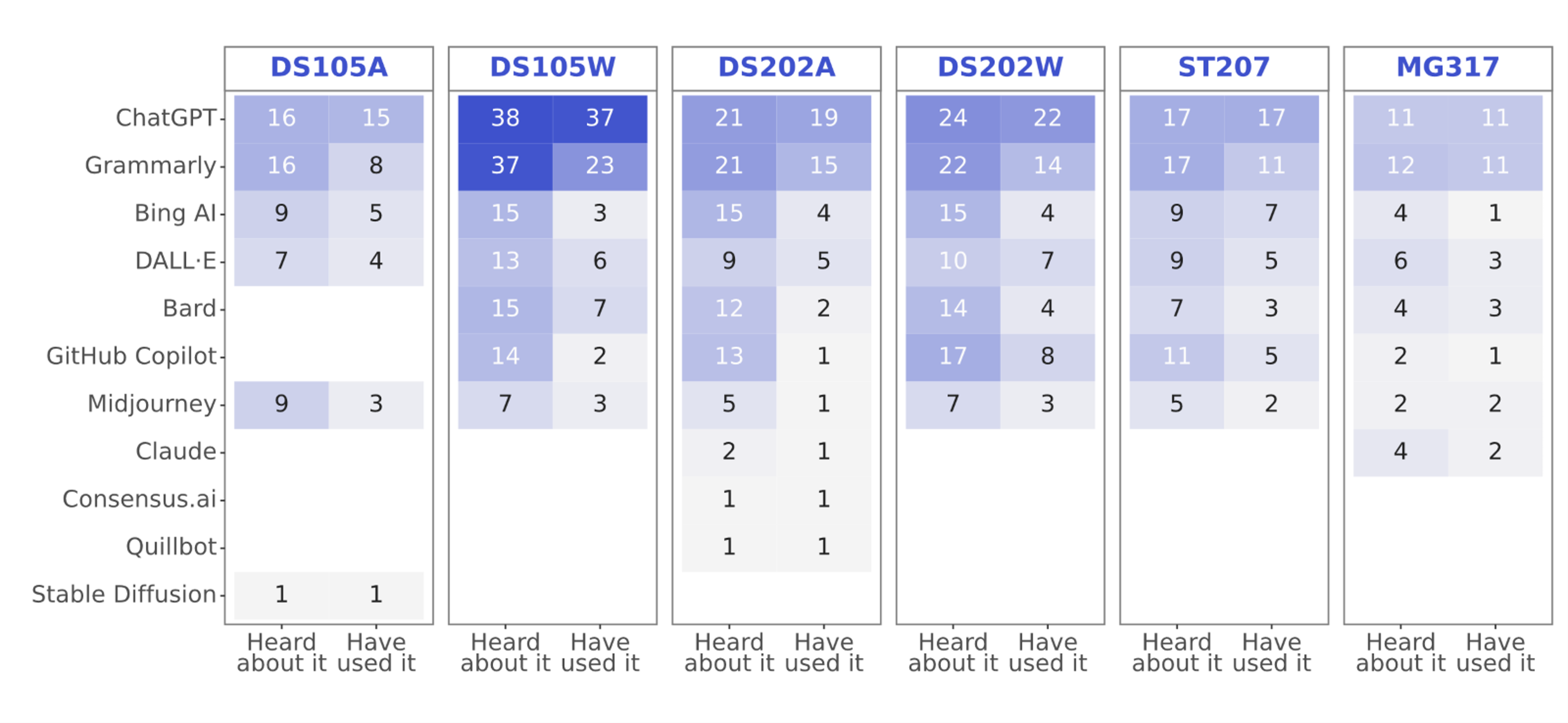
- ChatGPT dominated as the most used tool.
- Not every participant filled out the initial survey
Attitudes: AI for learning?

Attitudes: Any good?

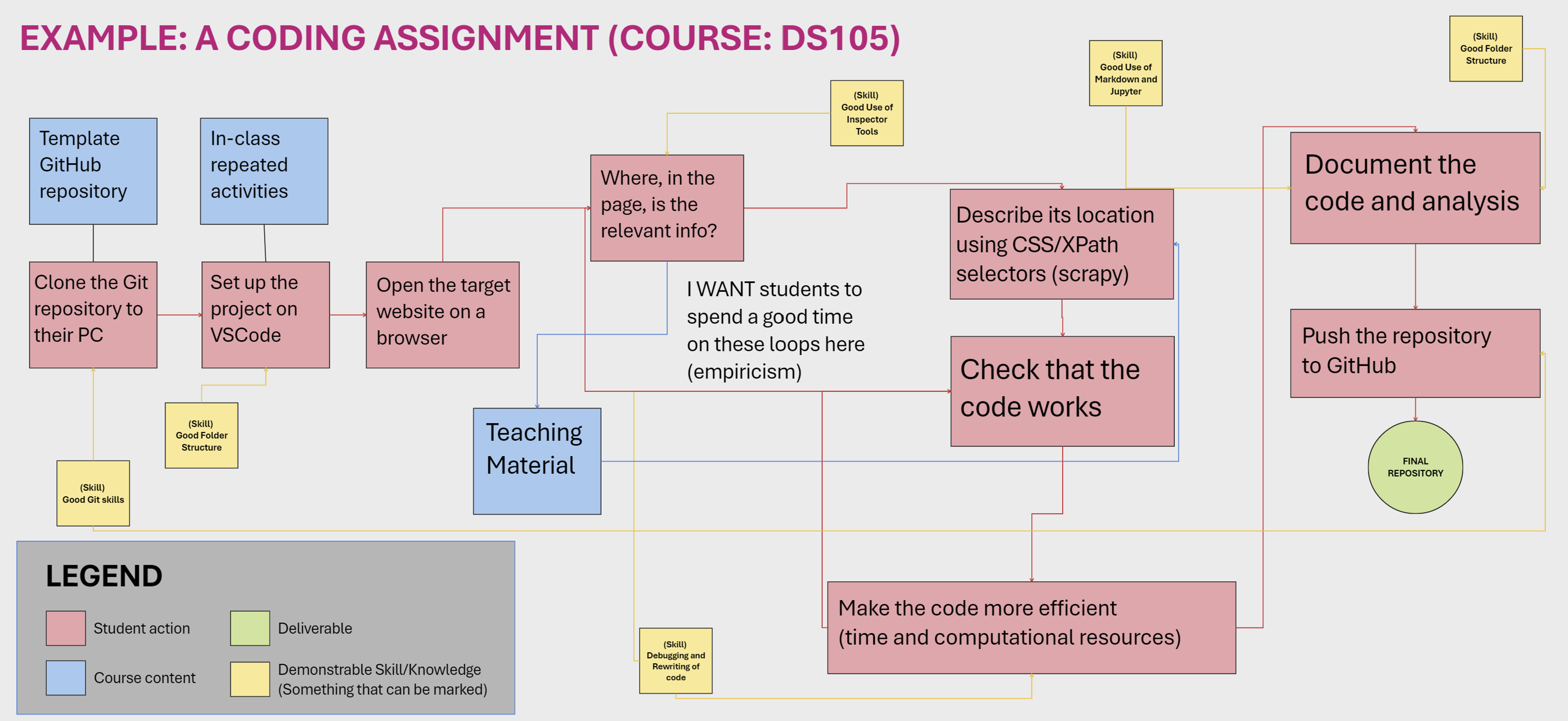
A bit of context about the DS105 course
- Lots of coding 👩💻
- As you may know, programming is an iterative process and frustration is a desirable difficulty we want our students to experience.
- I want students to:
- Understand the problem
- Break it into smaller, actionable pieces
- Figure out how to start
- Write a first draft
- Test it out
- Fix ‘bugs’
- Figure out what is the next step
- Go back to Step 3

Source: LSE DS105 website (lse-dsi.github.io/DS105)
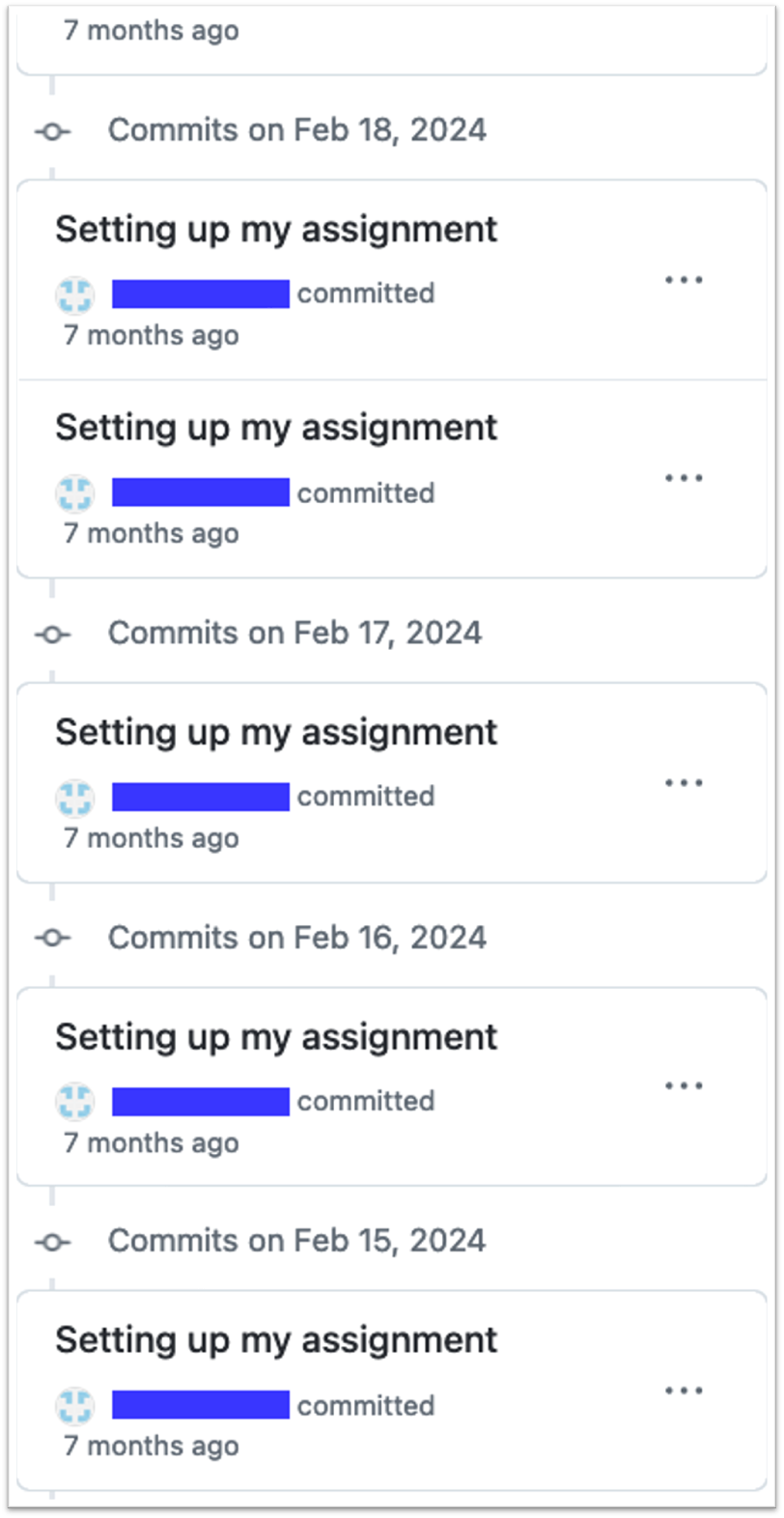
How Student A documented their drafts
Student A’s logs
- All draft updates had the same description 👉
- The student’s metacognition process was not engaged. The purpose of the git commits was not salient to them and became a mechanical step to complete.
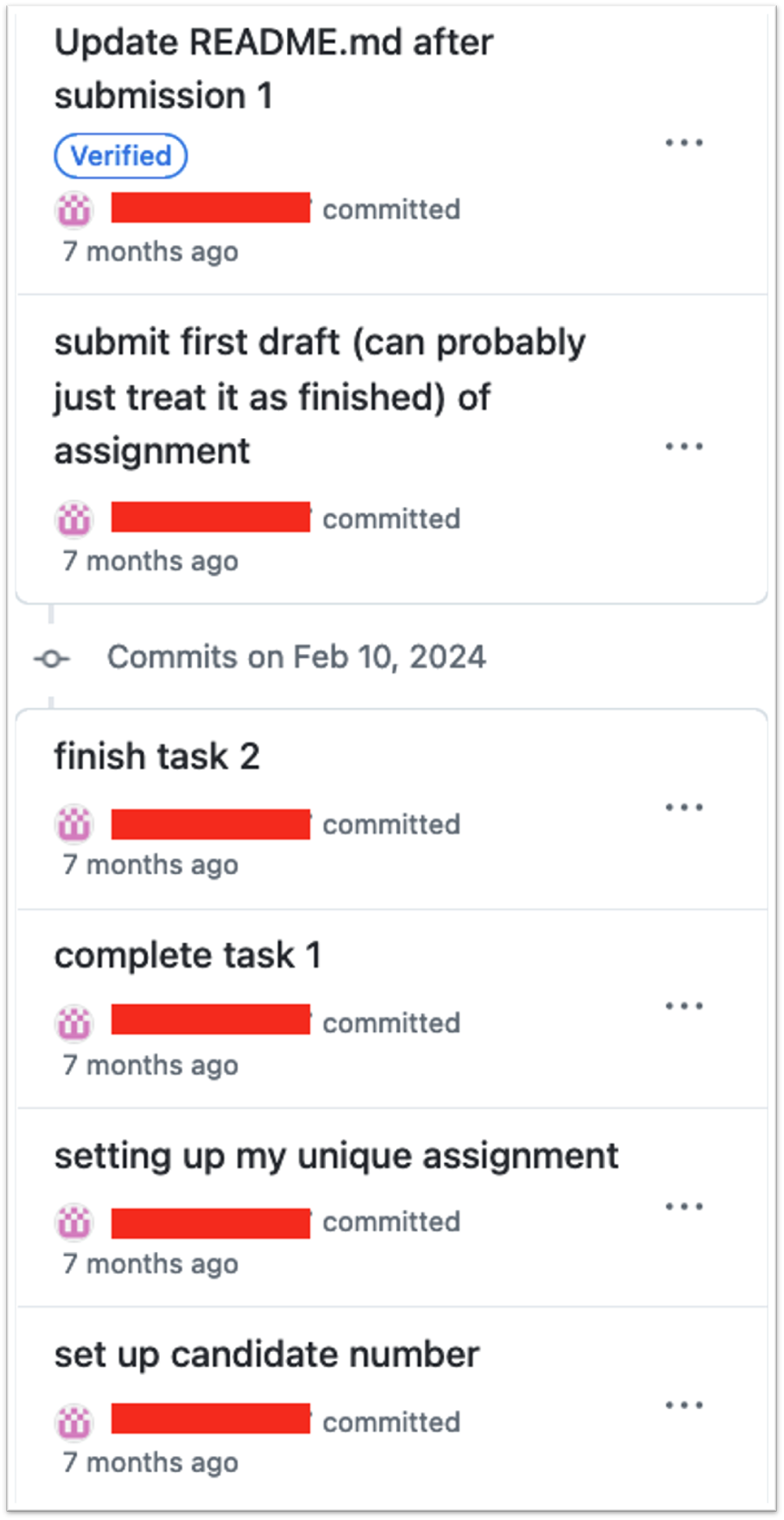
How Student B documented their drafts
Student B’s logs
- Added meaningful descriptions to their commits
- We know what their purpose was with every update
- This makes it possible to decode their thinking process more easily
Student B was a Resourceful user of AI

- Note also that the use intensifies when there is an assigment. This was common across ALL participants.
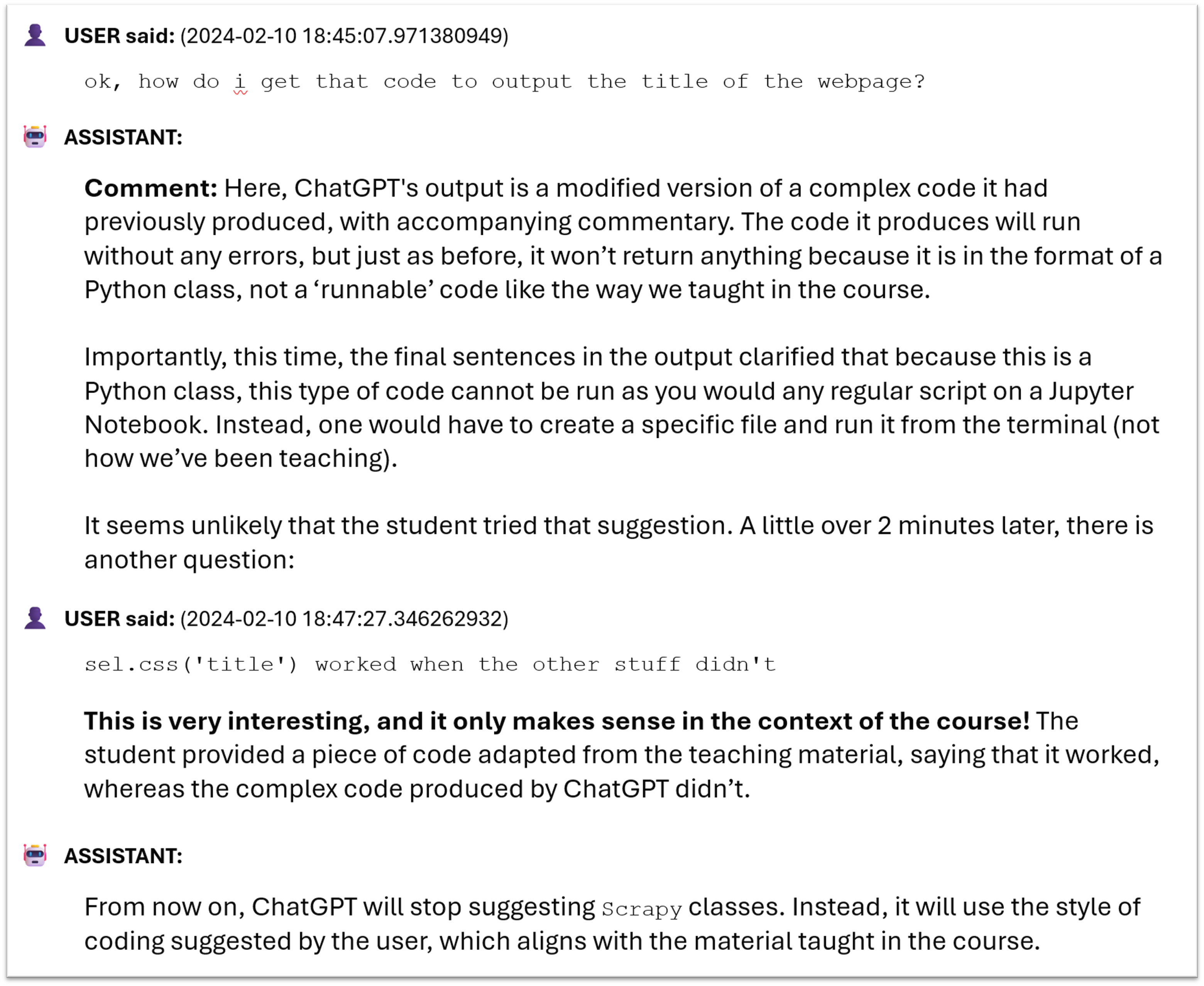
Student B challenged the AI
Student B’s logs
- ChatGPT often produced overcomplicated code
- The student went back to the teaching material and told the AI: “your stuff is not in line with what I learned”
- They were in control of their learning
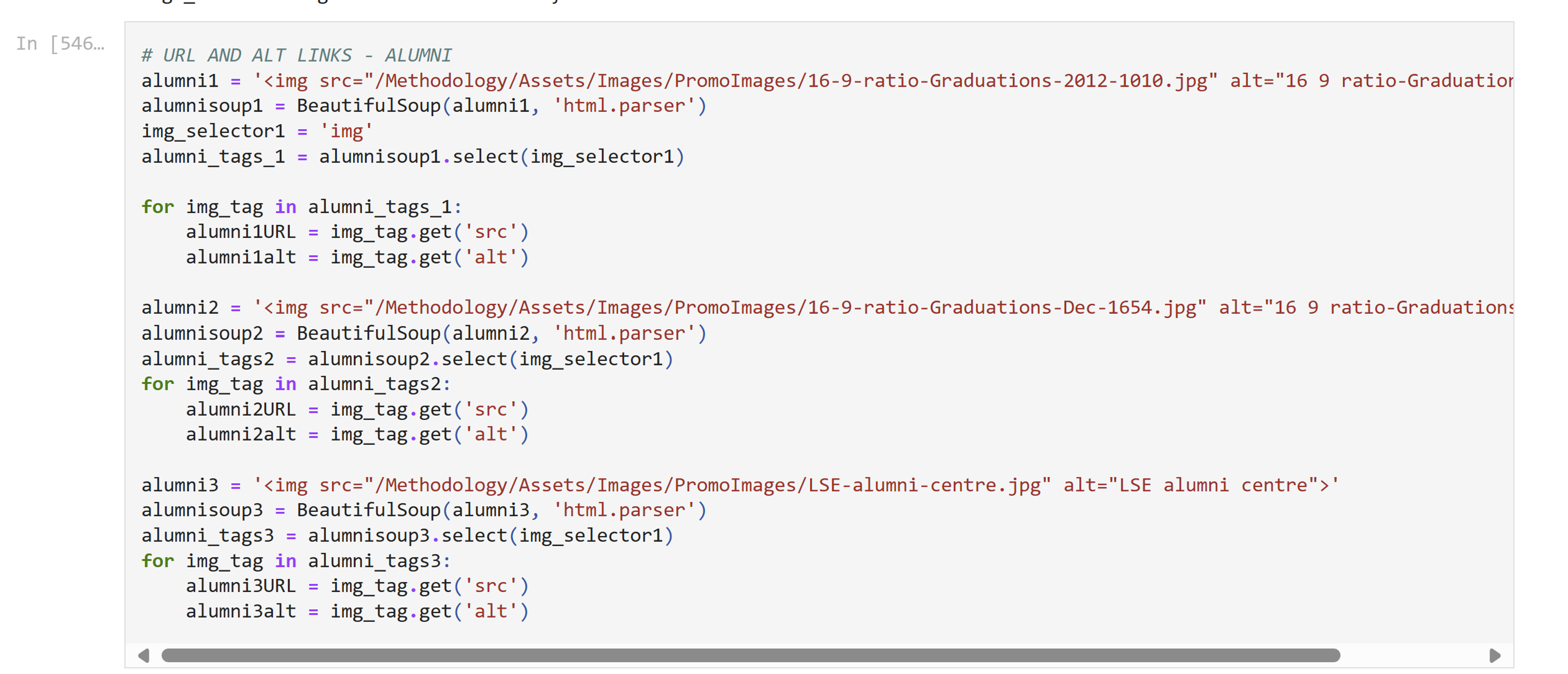
Student A was misled
The task involved writing code to:
Navigate to a pageGrab the entire content of that page- Select just the relevant information
- Clean it up
- Store it
Student A missed two crucial steps. They were misled by an inaccurate use of GenAI, clearly swayed by the chatbot’s authoritative tone.
Process-based assignments
As an educational researcher
Thank you

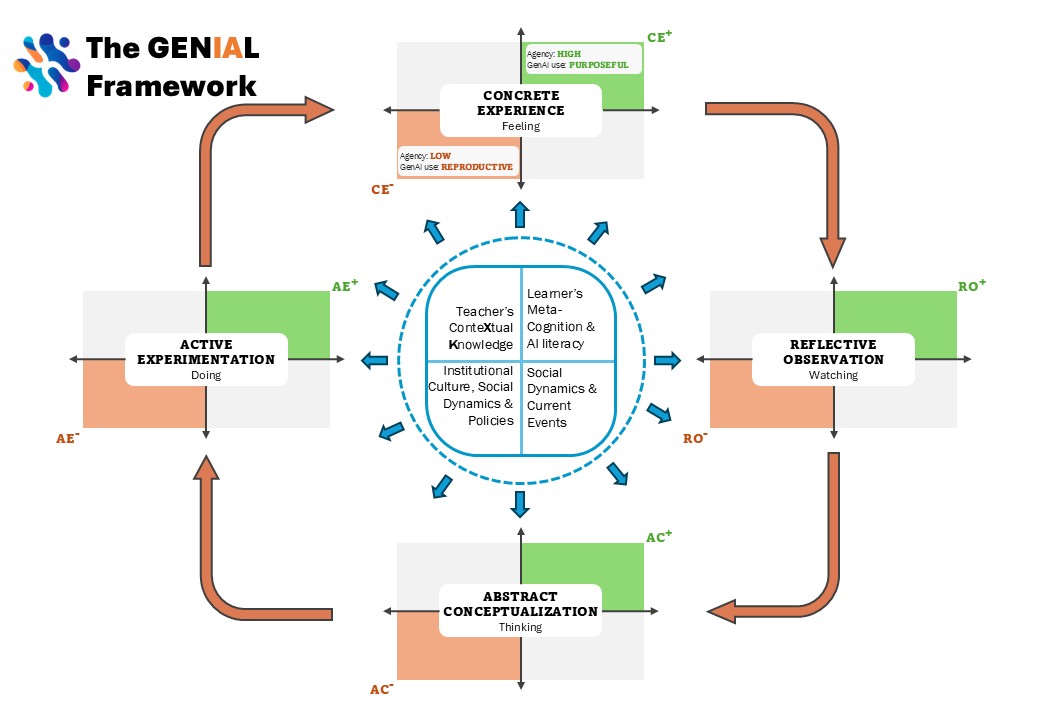
Cardoso-Silva, J., Sallai, D., Kearney, C., Panero, F., & Barreto, M. E. (2025). Mapping Student-GenAI Interactions onto Experiential Learning: The GENIAL Framework. SSRN Electronic Journal. (Under Review)

Sallai, D., Cardoso-Silva, J., et al. (2024). Approach Generative AI Tools Proactively or Risk Bypassing the Learning Process in Higher Education. LSE Public Policy Review, 3(3), 7.

